|
FORUMS PROFESSIONNELS
WINDEV, WEBDEV et WINDEV Mobile |
| | | | | |
| Problème de Performance HFSQL vs MYSQL |
| Débuté par Zack, 05 juil. 2018 18:22 - 28 réponses |
| |
| | | |
|
| |
Membre enregistré
127 messages
Popularité : +4 (6 votes) |
|
Posté le 05 juillet 2018 - 18:22 |
Bonjour à tous.
J'ai une base de données mysql d'un client qui dispose d'une table vd_commandes de 50K
sur le site original, lors du clic du bouton faire afficher les données de la table avec un simple select prend 2 secondes.
J'ai importé les donner mysql dans une DB HFSQL classique et j'ai créée une requête avec le même select, ça lui prend 7 secondes faire afficher les mêmes résultats.
J'ai effectivement ajouté des clefs sur ID , voici les requêtes en question.
// Prends 2 secondes pour s'exécuter. 50 mille enregistrements
$sqlACMD = "SELECT * FROM vd_commandes WHERE state=3 ORDER BY createDate DESC, no_bill";
$resultACMD = mysql_query($sqlACMD);
$nbCMD = mysql_num_rows($resultACMD);
Prends 7 secondes pour s'exécuter. 50 mille enregistrements
HExécuteRequête(REQ_VoirCmdParÉtat,hRequêteDéfaut,3)
SELECT
vd_commandes.id AS id,
vd_commandes.idClient AS idClient,
vd_commandes.idUser AS idUser,
vd_commandes.no_bill AS no_bill,
vd_commandes.ref AS ref,
vd_commandes.idShip AS idShip,
vd_commandes.idDest AS idDest,
vd_commandes.info AS Info,
vd_commandes.val_dec AS val_dec,
vd_commandes.createDate AS createDate,
vd_commandes.updateDate AS updateDate,
vd_commandes.state AS state,
vd_commandes.terme AS terme
FROM
vd_commandes
WHERE
vd_commandes.state = {ParamÉtat}
ORDER by
createDate DESC,
no_bill DESC
J'ai ajouté des clefs pour le champ state.
Analyseur de performance m'indique qu’il n’y a rien à faire pour améliorer les performances.
J'affiche les commandes dans une table, pour cette opération, c'est fait rapidement, c'est juste lorsque HExécuteRequête
Est-ce qu'il y a quelques chose que je peu faire pour améliorer les performances ???? Vu mes connaissances je pose la question pour savoir ce que je peux faire.
Merci.Message modifié, 05 juillet 2018 - 18:25 |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 568 messages
Popularité : +222 (260 votes) |
|
Posté le 06 juillet 2018 - 11:50 |
Bonjour,
Combien d'enregistrements ta table contient-elle au total ? Très honnêtement à part la clé sur State, il n'y a pas grand chose à faire. Rajoute tout de même une clé sur createDate et no_bill car ils effectuent le tri. La requête s'appuie probablement dessus. il faudrait voir le explain de la requête pour en être sûr et voir où passe le temps.
--
Cordialement,
Philippe SAINT-BERTIN |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
265 messages
Popularité : +14 (16 votes) |
|
Posté le 09 juillet 2018 - 11:59 |
Bonjour,
Maintenant il faut essayer la même chose sur une BDD HFSQL Client/Serveur ...
Je paris que les performances seront très différentes 
Cordialement
--
René MALKA |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
127 messages
Popularité : +4 (6 votes) |
|
Posté le 09 juillet 2018 - 13:26 |
Merci pour vos réponses.
Autant Classique que Client/Serveur c'est aussi long. 6-7 secondes pour un select, order by ou non, j'ai tenté de mettre une limit 1000, mais à cause du order by hfsql doit repasser tous les enregistrements pour les mettre en ordre et c'est la que ça rame.
La base de données dispose de 50,000 enregistrements. J'ai décidé d'importer la base de données de mysql à webdev en natif et de ne pas convertir et deviner quoi.
La même requête avec le même code en natif mysql, 2 fois plus rapide...... les bases de données sur sont le même serveur pourtant.
Je me suis fait avoir un peu avec ce moteur, payer 500billets pour m’apercevoir qu'un moteur gratuit est plus performant.... Je me suis fait endormir avec leurs pubs de 20 milliards d'enregistrements qui font apparaître un select quasi instantané. Utilisation d'une vu ? |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
265 messages
Popularité : +14 (16 votes) |
|
Posté le 09 juillet 2018 - 13:38 |
Cher Zack,
HFSQL est gratuit lui aussi
De part mon expérience je sais que les performances en matière de BDD est un sujet délicat où rien n'est absolu.
Je reste tout de même très étonné de ces résultat.
Il faudrait creuser...
Cordialement
--
René MALKA |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
950 messages
Popularité : +53 (63 votes) |
|
Posté le 09 juillet 2018 - 13:42 |
Bonjour,
La connexion à ta base hfsql c/s est compressé ? crypté ?
En HF classic, ton repertoire BDD est ou ? ton antivirus est en exception sur ce repertoire ?
il y a plein de chose qui rentre en ligne de compte en HF, comparé à MYSQL
Je gère des millions de ligne en HF et je vais beaucoup plus vite à les lire qu'en MYSQL.
quels sont les specs de ton serveur /pc developpement ?
ça peut jouer aussi
jordan |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
127 messages
Popularité : +4 (6 votes) |
|
Posté le 09 juillet 2018 - 15:34 |
Jordan a écrit :
Bonjour,
La connexion à ta base hfsql c/s est compressé ? crypté ?
Non crypter et pas compressé.
En HF classic, ton repertoire BDD est ou ? ton antivirus est en exception sur ce repertoire ?
Il se trouve dans le exe du projet web , J'ai démarré un projet windev et j'ai importé ma base de données pour tester directement sur mon poste.
Mais ce que je trouve étrange c'est que ma requête avec un LIMIT 1000 est aussi longue à traiter que la requête avec un select standard. Je ne comprends pas pourquoi la différence de performance est aussi grande.
il y a plein de chose qui rentre en ligne de compte en HF, comparé à MYSQL
Je gère des millions de lignes en HF et je vais beaucoup plus vite à les lire qu'en MYSQL.
quels sont les specs de ton serveur /pc developpement ?
J'ai un Xeon X5670 2.93ghz 2 processeurs, 24gig ram, 600gig de HD en raid 1. ce serveur est dédié à HFSQL seulement aucune autre appli ne fonctionne dessus à part mysql que je viens d'installer, le serveur n'a pas d'antivirus pour le moment, c'est mon serveur de developpement test.
ça peut jouer aussi
jordan |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 568 messages
Popularité : +222 (260 votes) |
|
Posté le 10 juillet 2018 - 12:24 |
Bonjour,
Peux-tu poster une capture de la description de ton fichier HFSQL ?
--
Cordialement,
Philippe SAINT-BERTIN |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
127 messages
Popularité : +4 (6 votes) |
|
Posté le 10 juillet 2018 - 17:38 |
Plus simple voici la BD, Ce n'est pas des données sensible alors.
infochic.ca/1/vd_commandes.zip
et la requête.
SELECT TOP 100
vd_commandes.id AS id,
vd_commandes.idClient AS idClient,
vd_commandes.idUser AS idUser,
vd_commandes.no_bill AS no_bill,
vd_commandes.ref AS ref,
vd_commandes.idShip AS idShip,
vd_commandes.idDest AS idDest,
vd_commandes.info AS Info,
vd_commandes.val_dec AS val_dec,
vd_commandes.createDate AS createDate,
vd_commandes.updateDate AS updateDate,
vd_commandes.state AS state,
vd_commandes.terme AS terme
FROM
vd_commandes
WHERE
vd_commandes.state = {ParamState}
ORDER by
createDate DESC,
Les paramêtres sont 1,2,3 celui qui le plus long est le 3, dans un projet windev importer la bd dans l'analyse faite une requête et tester la requête dans l'éditeur de requête. elle prend 4-5 secondes à s’exécuter en classique. sur un serveur C/S elle passe à 6-7 pour une page web déployé, et prenez note que il y a un limit 100. Cette même requête en mysql natif prend 1 secondes à s’exécuter avec le même projet. |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 568 messages
Popularité : +222 (260 votes) |
|
Posté le 10 juillet 2018 - 22:32 |
Je voudrais la description de la table pour voir les index qui sont créés. Tu devrais modifier le libelle info car c'est un mot reserve
--
Cordialement,
Philippe SAINT-BERTIN |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
950 messages
Popularité : +53 (63 votes) |
|
Posté le 10 juillet 2018 - 22:36 |
Bonjour,
je viens de prendre ta base, j'ai rajouter une clé composé "createDate+id+idClient+idDest+idShip+idUser+no_bill+ref+state+terme+updateDate+val_dec",
La requête s'execute en 1s sans parametre pour afficher les 48575 resultats
Voila ce que j'ai fait pour tester
// Démarrage du chronomètre
ChronoDébut()
HExécuteRequête(REQ_test)
HNbEnr(REQ_test)
// Arrêt du chronomètre
DuréeMaFonction est une Durée = ChronoFin()
Info("Le traitement MaFontion() a duré " + DuréeMaFonction..EnSecondes) // affiche 1.039 secondes
JordanMessage modifié, 10 juillet 2018 - 22:38 |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 568 messages
Popularité : +222 (260 votes) |
|
Posté le 11 juillet 2018 - 08:13 |
Bonjour,
il est complètement inutile de créer une clé aussi importante, c'est plus pénalisant qu'autre chose. Elle n'est d'ailleurs pas du tout optimisée pour ta recherche.
Lorsqu'on crée une clé il faut qu'elle soit adaptée aux champs sur lesquels on effectue la recherche et si l'index est composé, la recherche doit respecter l'ordre de déclaration des champs de l'index.
Ici tu as juste à créer une clé sur state puisque c'est ce que tu recherches. La table étant indexée sur ce champ, la recherche va être extrêmement rapide. Il faut voir l'index comme un tri préalable de la table. tri étant effectué en amont par le moteur , la recherche des enregistrements va se baser là dessus pour rechercher et non plus lire la totalité de la table.
Voici mes tests après avoir mis state comme clé. L'exécution de la requête est très rapide, quelques millisecondes. La récupération ou lecture est plus longue ce qui est normal vu le nombre d'enregistrements que tu récupères, aux alentours de 3 s.
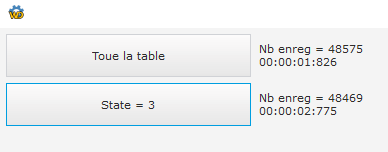
N.B: Voici de quoi comprendre le fonctionnement des index si ç at'intéresse https://blog.developpez.com/sqlpro/p9816/langage-sql-norme/tout_sur_l_index
--
Cordialement,
Philippe SAINT-BERTINMessage modifié, 11 juillet 2018 - 08:15 |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
950 messages
Popularité : +53 (63 votes) |
|
Posté le 11 juillet 2018 - 09:28 |
Je n'ai créé la clé que pour l'exemple, car tu lui avait conseillé d'en faire une mais visiblement ne l'a pas fait,
Je suis d'accord avec toi à 100%
Jordan
Philippe SB a écrit :
Bonjour, il est complètement inutile de créer une clé aussi importante, c'est plus pénalisant qu'autre chose. Elle n'est d'ailleurs pas du tout optimisée pour ta recherche. Lorsqu'on crée une clé il faut qu'elle soit adaptée aux champs sur lesquels on effectue la recherche et si l'index est composé, la recherche doit respecter l'ordre de déclaration des champs de l'index. Ici tu as juste à créer une clé sur state puisque c'est ce que tu recherches. La table étant indexée sur ce champ, la recherche va être extrêmement rapide. Il faut voir l'index comme un tri préalable de la table. tri étant effectué en amont par le moteur , la recherche des enregistrements va se baser là dessus pour rechercher et non plus lire la totalité de la table. Voici mes tests après avoir mis state comme clé. L'exécution de la requête est très rapide, quelques millisecondes. La récupération ou lecture est plus longue ce qui est normal vu le nombre d'enregistrements que tu récupères, aux alentours de 3 s. N.B: Voici de quoi comprendre le fonctionnement des index si ç at'intéresse https://blog.developpez.com/sqlpro/p9816/langage-sql-norme/tout_sur_l_index-- Cordialement, Philippe SAINT-BERTIN Message modifié, 11 juillet 2018 - 08:15 |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
127 messages
Popularité : +4 (6 votes) |
|
Posté le 11 juillet 2018 - 11:16 |
Philippe SB a écrit :
Bonjour,
il est complètement inutile de créer une clé aussi importante, c'est plus pénalisant qu'autre chose. Elle n'est d'ailleurs pas du tout optimisée pour ta recherche.
Lorsqu'on crée une clé il faut qu'elle soit adaptée aux champs sur lesquels on effectue la recherche et si l'index est composé, la recherche doit respecter l'ordre de déclaration des champs de l'index.
Ici tu as juste à créer une clé sur state puisque c'est ce que tu recherches. La table étant indexée sur ce champ, la recherche va être extrêmement rapide. Il faut voir l'index comme un tri préalable de la table. tri étant effectué en amont par le moteur , la recherche des enregistrements va se baser là dessus pour rechercher et non plus lire la totalité de la table.
Voici mes tests après avoir mis state comme clé. L'exécution de la requête est très rapide, quelques millisecondes. La récupération ou lecture est plus longue ce qui est normal vu le nombre d'enregistrements que tu récupères, aux alentours de 3 s.
Merci, J’obtiens un résultat en 3-4 secondes avec la clef sur state, createdate et no_bill.
À noter que la requête je la teste directement dans l'éditeur de requête. C'est effectivement rapide tout de même pour 50k d'enregistrements. Le problème c'est que pour du Web c'est long, je teste la bd sur un projet windev ...... j'Imagine le résultat en HFSQL C/S ...... et même si je mets une limite de 1000, cela ne change rien...... aucun gain de performance, anciennement le site tournait en PHP avec MySQL et avec la même requête le résultat est presque qu'instantané. Je vois mal expliquer à mon client mon résultat.
Alors j'ai décidé d'utiliser MySQL en natif avec sa base de données, et c'est beaucoup plus rapide.... et ça avec le même code... Inutile de faire afficher 50,000 enregistrements... si au moins le limité avait fonctionné, j'aurais gardé HFSQL... car MySQL en natif, le debug en réseau local... fait figer mon navigateur car webdev semble ne pas garder la connexion active.
Merci pour votre aide. |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 568 messages
Popularité : +222 (260 votes) |
|
Posté le 11 juillet 2018 - 15:17 |
As-tu réellement besoin de tous ces résultats ?
Bon après j'avoue que HFSQL a de grosses lacunes à ce point de vue. Mais comme je doute que ça change un jour, reste sur MySQL qui semble plus correspondre à tes besoins.
--
Cordialement,
Philippe SAINT-BERTINMessage modifié, 11 juillet 2018 - 15:21 |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
950 messages
Popularité : +53 (63 votes) |
|
Posté le 11 juillet 2018 - 15:44 |
Autre question,
Ton projet webdev est en AWP ou dynamique ?
Jordan |
| |
| |
| | | |
|
| | |
| |
Posté le 11 juillet 2018 - 15:44 |
De mon expérience, une grande taille d'enregistrement ralenti considérablement HFSQL (et tu peux remplir chaque colonne avec du vide (NULL), la taille du fichier sur le disque=nbre de lignes*taille enregistrement)
On a eu le problème avec une base sur laquelle on mixte du relationnel et un ersatz de NoSQL (la table principale contient plus de 300 colonnes). C'est inutilisable avec HFSQL, mais on a d'excellentes perfs avec MySQL (alors que HFSQL est sur mon réseau local et MySQL sur un hébergement mutualisé low cost)
Par contre, chez d'autres clients, tout fonctionne parfaitement en HFSQL, avec des fichiers de plusieurs millions de lignes (mais pour le coup c'est un vrai modèle relationnel, beaucoup de tables, beaucoup de lignes mais des enregistrements de taille relativement courtes). |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
265 messages
Popularité : +14 (16 votes) |
|
Posté le 11 juillet 2018 - 16:46 |
Bonjour,
Je vais aussi apporter ma petite pierre, pour relativiser un peu tout cela et en évoquant un projet professionnel d'envergure.
Jugez plutôt :
- Un projet principal en Webdev et 5 projets périphériques en Windev
- Un petit peu plus de 100 000 lignes en tout
- 67 pages, 189 classes et 429 requêtes
- 7 bases de données de prod et 3 de tests, qui peuvent se matérialiser sous HFSQL, SQL Server ou Oracle
- Modèle classique avec des pages qui s'appuient sur des classes qui elles-même s'appuient sur des requêtes
- De 4 à 6 niveaux d'abstractions selon les besoins métiers
Un des clients intègre un jeu de BDD d'environ 150Go de données sous HFSQL
Avec des fichiers en dizaines de colonnes et en millions de lignes.
Et bien chez ce client, malgré le nombre élevé de niveaux d'abstractions, une requête, même parmi les plus alambiquées, ne répond jamais en plus de 4 secondes...
Cordialement
--
René MALKA |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
127 messages
Popularité : +4 (6 votes) |
|
Posté le 11 juillet 2018 - 20:40 |
René a écrit :
Bonjour,
Je vais aussi apporter ma petite pierre, pour relativiser un peu tout cela et en évoquant un projet professionnel d'envergure.
Jugez plutôt :
- Un projet principal en Webdev et 5 projets périphériques en Windev
- Un petit peu plus de 100 000 lignes en tout
- 67 pages, 189 classes et 429 requêtes
- 7 bases de données de prod et 3 de tests, qui peuvent se matérialiser sous HFSQL, SQL Server ou Oracle
- Modèle classique avec des pages qui s'appuient sur des classes qui elles-même s'appuient sur des requêtes
- De 4 à 6 niveaux d'abstractions selon les besoins métiers
Un des clients intègre un jeu de BDD d'environ 150Go de données sous HFSQL
Avec des fichiers en dizaines de colonnes et en millions de lignes.
Et bien chez ce client, malgré le nombre élevé de niveaux d'abstractions, une requête, même parmi les plus alambiquées, ne répond jamais en plus de 4 secondes...
Cordialement
--
René MALKA
René j'aimerais connaître la config de ce serveur.
Je crois que tout dépend des performances de la machine et du CPU et du moteur, j'ai exécuté la même requête que Jordan, et j'obtiens un résultat de trois secondes tandis que lui l'obtient en une sec. Pourtant j'ai un Alienware i7-7820HK 2.90 32gig ram, SSD 970 PRO NVMe M.2 512 gig
Cela fait deux jours que je teste plusieurs scénarios, avec clefs composer etc.. .. et c'est vrai que c'est plus rapide. Mais pour être honnête HFSQL n'est pas le moteur le plus rapide dut marcher.
J'ai faits des comparaisons, même code sur un projet-test en local avec une BD classique, HFSQL est aussi rapide que Mysql avec un simple select.
Quand on commence à mettre des jointures ou des conditions cela ce Corse et Mysql est supérieur. vd_commandes est qu'une seule table, j'ai également vd_clients et si je tente de faire une jointure avec ma table clients je peux compter 8 à 12 secondes avant d'avoir un résultat.
René j'aimerais connaître la config de ce serveur. Car 100,000 enregistrements en dedans de quatre secondes, est-ce que ce sont des simples select ou il y a des jointures.
Je suis en colère car j'aurais voulu utilisé HFSQL car mon client veut que je développe une APP mobile qui communiquera avec la base de données et HFSQL est conçu pour cela. Je vais réussir aussi en natif mais cela sera plus compliqué.. |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
950 messages
Popularité : +53 (63 votes) |
|
Posté le 11 juillet 2018 - 22:34 |
un Alienware i7-7820HK 2.90 32gig ram, SSD 970 PRO NVMe M.2 512 gig
Moi Je suis sur un macbook Pro 15 retina mid 15 i7-4770HQ 2,5 GHz 16go 500 Go SSD et le windows est virtuel sous parallels Desktop avec 4 vCpu et 5go de ram et 120Go de HDD
Jordan |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
265 messages
Popularité : +14 (16 votes) |
|
Posté le 12 juillet 2018 - 08:06 |
Bonjour,
Zack, sincèrement je ne sais pas !
Ce client est à l'étranger et tient à son autonomie quand au matériel utilisé.
De toute façon, à une époque où la puissance de calcul d'un smartphone n'est pas loin de celle d'un ordinateur personnel, ce n'est plus un critère si déterminant que cela. En revanche, des choses comme la qualité de l'analyse et les jointures, si !
Zack, bien entendu que HFSQL n'est pas le système de BDD le plus rapide, nous nous en compte quand on fait des comparatifs avec Oracle par exemple : rien à voir ! Cependant, nous ne l'avons pas fait avec MySQL qui n'a pas été prévu car jamais demandé par un client.
Quand on conçoit une analyse qui doit permettre de fonctionner à la fois sur 3 type de BDD on a des contraintes qui obligent à être rigoureux. Et c'est peut-être de ce côté là qu'il faut voir. Par exemple, et effectivement, pas de beaucoup de jointures.
Bref, HFSQL n'est peut-être pas le plus rapide mais pas au point d'avoir des temps de réponses > à 4 seconde en moyenne.
Quand il y a dépassement de certain seuils il faut prendre le temps de creuser et de trouver des cause d'abord et avant tout au niveau du développeur avant de blâmer les outils.
Cordialement
--
René MALKA |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
127 messages
Popularité : +4 (6 votes) |
|
Posté le 12 juillet 2018 - 10:26 |
Effectivement, ce lien répond en quelque sorte à mon questionnement de performance...
https://db-engines.com/fr/ranking HFSQL est loin derrière
Je ne comprendrais sûrement jamais PCSOFT qui semble prendre un plaisir à réinventer la roue, c'est un peu comme l'éditeur d'image que je me sers jamais... bon faut bien mettre du beurre sur les rôtis. À trop vouloir s'élargir sur différentes options de version en version ils semblent oublier l’essentiel, les " bogues " et les clients.
Je râle là mais j'aime le concept unique du logiciel, j'ai quand même payé le pactole pour la suite WD.
Merci à tous ceux qui ont pris la peine de m'aider avec mon problème. |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 568 messages
Popularité : +222 (260 votes) |
|
Posté le 12 juillet 2018 - 11:18 |
@René: Je suis plutôt assez d'accord avec Zack pour le coup, j'ai fait le test avec sa base, un fichier et 50 000 enregs les clés posées au bons endroits et je dois avouer qu'on est au minimum à 3 s. C'est long, trop long même. Le plus étrange c'est que ce n'est pas le moteur qui est l eplus pénalisant car la requête sort entre 15 et 20 ms donc acceptable. Mais le traitement juste pour HNbEnr est très long.
--
Cordialement,
Philippe SAINT-BERTIN |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
265 messages
Popularité : +14 (16 votes) |
|
Posté le 12 juillet 2018 - 14:21 |
Bonjour à nouveau,
Zack, Philippe, en étudiant le classement des systèmes de BDD (HFSQL 150 ème ! oO) je me suis rendu compte que nous n'avions pas parlé des versions de MySQL utilisées. Après la reprise de MySQL par la Sté Oracle et le début de fork avec MariaDB, je me souviens que les courses en versions on commencé et que cela a été tendu. Mais je n'e l'ai pas suivi depuis longtemps. Si j'en crois ce classement, qui n'est que ce qu'il est, Oracle a mis le paquet pour que MySQL ne se fasse pas distancier par MariaDB !
Bref, je ne comprend toujours pas ce qui se passe avec cette base de donnée vd_commandes :
- Je l'ai récupéré et j'ai créé un mini projet rien que pour elle !
- Ensuite j'ai fait un test comme celui de Jordan avec un HNbEnreg
- J'ai ensuite transférer le fichier en HFSQL Client Serveur et j'ai effectué le même test
- Et pour finir j'ai créé une Bdd MySQL dans laquelle j'ai créé aussi un fichier pour transvaser vd_commandes
- Et j'ai lancé le même test que précédemment.
Résultats :
- HFSQL Classic v23 : 1.196 sec
- HFSQL C/S v23 : 1.002 sec
- MySQL v5.6.17 : 0.26 sec
Il n'y a pas photo !
Vous en tirerez seuls les conclusions évidentes
Zack, pour ce qui est de ton dernier argument, c'est moi aussi ce que je clame depuis des années.
Cependant les choses avancent, lentement mais elles avancent...
Cordialement
--
René MALKA |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 568 messages
Popularité : +222 (260 votes) |
|
Posté le 13 juillet 2018 - 08:08 |
Bonjour à tous,
Comme René j'ai fait mes tests avec PostgreSQL et là je crois que les résultats sont sans appel.
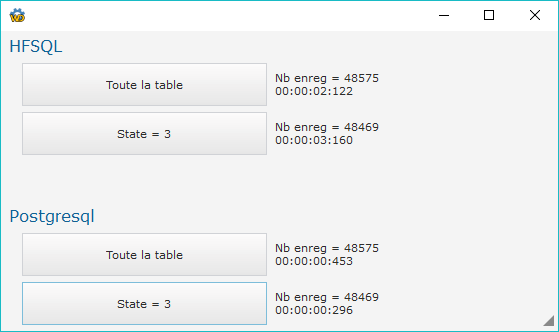
Je me demande comment il peut y avoir tant de différences. Je précise que je suis sur un portable qui n'a qu'un petit Core i5 1.70 GHz et que je n'ai que 8 Go de RAM.
Ca fait des années que je milite pour une évolution profonde du moteur HFSQL pour en faire un vrai SGBD comme tant de bases gratuites MariaDB, PostgreSQL ou MySQL (selon l'utilisation faite).
Peut-être que la vue des ces différents tests feront bouger un peu le cocotier… Gardons espoir.
Comme vous je suis un fervent défenseur de WD. Malgré le fait que ça n'évolue pas assez vite à mon goût, je trouve que sa simplicité d'utilisation et sa rapidité pour le développement est un véritable atout.
--
Cordialement,
Philippe SAINT-BERTIN |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
127 messages
Popularité : +4 (6 votes) |
|
Posté le 13 juillet 2018 - 11:26 |
Philippe, comment tu as converti la BD ?? |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 568 messages
Popularité : +222 (260 votes) |
|
Posté le 13 juillet 2018 - 11:35 |
j'ai juste passé un script. quelque chose comme ça (je ne l'ai pas sous les yeux donc c'est à la volée).
Attention !!! par convention les colonnes en PostgreSQL sont en minuscule. Il faut donc passer le nom de toutes tes rubriques en minuscule pour ne pas avoir de problème, sinon tu vas avoir un message d'erreur disant que la colonne n'existe pas.
tabEnregs est tableau de Enregistrements de vd_commandes
POUR TOUT vd_commandes
tabEnregs.ajoute(vd_commandes)
FIN
HChangeConnexion(vd_commandes,cnxPostgresql)
POUR TOUT enreg de tabEnregs
HRAZ(vd_commandes)
vd_commandes = enreg
HAjoute(vd_commandes)
FIN
Sinon tu as une autre méthode que je n'ai pas testé, c'est de faire un COPY en requête sql sur PostgreSQL à partir d'un fichier csv. Je l'utilise pour des gros volumes, mais là pour le peu de données qu'il y a la première méthode va bien.
--
Cordialement,
Philippe SAINT-BERTIN |
| |
| |
| | | |
|
| | |
| |
Posté le 26 juillet 2018 - 10:32 |
Philippe SB avait énoncé :
Bonjour à tous, Comme René j'ai fait mes tests avec PostgreSQL et là je crois que les résultats sont sans appel.
Je me demande comment il peut y avoir tant de différences. Je précise que je suis sur un portable qui n'a qu'un petit Core i5 1.70 GHz et que je n'ai que 8 Go de RAM. Ca fait des années que je milite pour une évolution profonde du moteur HFSQL pour en faire un vrai SGBD comme tant de bases gratuites MariaDB, PostgreSQL ou MySQL (selon l'utilisation faite). Peut-être que la vue des ces différents tests feront bouger un peu le cocotier… Gardons espoir. Comme vous je suis un fervent défenseur de WD. Malgré le fait que ça n'évolue pas assez vite à mon goût, je trouve que sa simplicité d'utilisation et sa rapidité pour le développement est un véritable atout.
je fais aussi partie des défenseurs de WB/WD mais pour moi la base de
données, c'est pas le boulot de pcsoft.
vivent les standards reconnus !
donc pour moi c'est mysql depuis très longtemps (avant c'éatit Oracle)
et je m'en porte très bien !
... même si sur le coup du cryptage because rgpd, mysql a marqué des
points dans mon estime
---
Cet email a fait l'objet d'une analyse antivirus par AVG.
http://www.avg.com |
| |
| |
| | | |
|
| | |
| |
Posté le 26 juillet 2018 - 14:27 |
Roumegou Eric a utilisé son clavier pour écrire :
Philippe SB avait énoncé :
... même si sur le coup du cryptage because rgpd, mysql a marqué des points dans mon estime
il fallait lire hf sql bien sûr
---
Cet email a fait l'objet d'une analyse antivirus par AVG.
http://www.avg.com |
| |
| |
| | | |
|
| | | | |
| | |
| | |
| |
|
|
|