| |
Membre enregistré
31 messages |
|
Posté le 15 septembre 2020 - 17:16 |
Bonjour
J ai fini une application qui doit principalement extraire des données dans des fichiers pdf.
J ai tenté la fonction PDFVERSTEXTE et ça devient très brouillon quand j'obtiens le résultat et je n'obtiens aucun indicateur pour extraire mes données
Dois je changer de version ? Est ce que la version 25 offre une meilleure solution?
Merci
Christine |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
160 messages
Popularité : +18 (22 votes) |
|
Posté le 15 septembre 2020 - 17:59 |
Bonjour,
essaie l'assemblage .net ' TikaOnDotnet.TextExtractor' |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 15 septembre 2020 - 18:20 |
Bonjour
J ai regardé sur internet . Je ne vois malheureusement pas comment faire avec cette solution.
Merci pour cette réponse |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
329 messages
Popularité : +28 (32 votes) |
|
Posté le 15 septembre 2020 - 18:43 |
Moi, j’utilise PDFversTexte, Et j’ai pris le temps d’analyser le texte résultant afin d’y trouver des repères sur lesquels m’appuyer pour trouver les valeurs que je dois y trouver.
--
———————————————————————————————————
Ce qui se conçoit bien se code clairement et se débogue facilement...
- Pastiche d’une citation de Nicolas Boileau - |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 15 septembre 2020 - 18:55 |
les valeurs et les libellés que je dois trouver ne sont pas alignés .J ai pris le temps d'analyser mais d'un fichier à un autre un fichier je n ai pas le même résultat . Ce sont des valeurs de labo que je dois extraire. Je ne peux pas faire une fonction pour chaque malheureusement feuille et pour chaque labo . |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 15 septembre 2020 - 18:58 |
Et je n'ai pas d indicateur mis à part des sauts de ligne retour chariot . Parfois j ai 3 valeurs alignées et on se demande de quel libellé elles appartiennent . |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 15 septembre 2020 - 20:33 |
Pour l'assemblage .net ' TikaOnDotnet.TextExtractor' il faut une version aussi? je ne la vois pas dans la liste.... |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
962 messages
Popularité : +183 (185 votes) |
|
Posté le 16 septembre 2020 - 07:57 |
hello,
TikaOnDotnet.TextExtractor est une véritable usine à gaz car il faut installer une trentaine d'assemblages annexes pour le faire fonctionner sous windev. De plus je ne suis pas sur que cela te donne de meilleurs résultats qu'avec PDFVERSTEXTE ou d'autres extracteurs. Comme l'indiquer Dergen, dans le texte extrait il faut prendre des repères ( des textes qui sont toujours présents et qui délimitent ce que l'on veut extraire). Avec des expressions régulières ça doit être possible alors d'extraire les données que l'on veut.
Si tu pouvais nous donner des parties (plusieurs cas différents) de ce qu'extrait PDFVERSTEXTE et de ce que tu veux récupérer, on pourrait te dire si cela est possible. Si les données sont confidentielles ne mettre qu'un extrait de ce qui n'est pas confidentiel.
--
Ami calmant, J.P |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 16 septembre 2020 - 08:14 |
J ai deux exemples
exemple 1
TSH 3ème génération (1)
8.593 mUI/l
là ok saut de ligne je peux gérer j ai la valeur de ma TSh
Exemple 2 ça se complique
TSH 3ème génération (1)
4.131 mUI/l 133.60 UI/ml 10.70 UI/ml
Anticorps anti THYROPEROXYDASE (TPO) (1)
Anticorps anti tg
J ai 3 valeurs alignées une qui correspond à la TSH L'autre aux anticorps TPO l autre anti tg.
Ce ne sont que deux exemples .
Je n ai pas d'indicateurs |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 16 septembre 2020 - 08:43 |
Un autre exemple :
TSH 3ème génération (1)
3,35 2,18
pmol/l pg/ml
3,10 à 6,80 2,02 à 4,43
5,52
Parmi toutes ces valeurs c est la dernière qu'il faut prendre(5.52) . Voilà déjà 3 exemples différents
Est que la version 25 offre une soluton? |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
962 messages
Popularité : +183 (185 votes) |
|
Posté le 16 septembre 2020 - 08:59 |
Ce n'est pas la version 25 de windev qui va pouvoir résoudre ton problème, c'est la possibilité de caractériser ce qui doit être extrait. Est-ce que le PDF est constitué de tableaux ?
Est-ce que TSH et ses données et toujours suivi par un texte fixe ? si oui peux-tu nous montrer ce que c'est. Si non est-ce la fin de l'extraction ?
--
Ami calmant, J.P |
| |
| |
| | | |
|
| | |
| |
Posté le 16 septembre 2020 - 09:07 |
Pour les pdf structurés, la version 25 apporte des améliorations. Non pas sur la fonction pdfverstexte, mais il devient possible d'extraire chaque zone texte avec son emplacement. (en utilisant l'extraction des élément d'une variable pdfdocument)
Pour ma part, pour analyser les pdf, j'utilisais pdfverstexte, mais aussi l'utilitaire pdftotext.exe (ne nécessite pas d'installation) sui donne un meilleur résultat sur l'emplacement des textes. |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 16 septembre 2020 - 09:23 |
Lorsque j execute ma fonction pdfverstexte j 'utilise un champ multiligne pour recupérer mon texte.
Comment savoir si mon pdf est un tableau ?. Texte brut avec saut de ligne et retour chariot comme montré ci dessus. |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
962 messages
Popularité : +183 (185 votes) |
|
Posté le 16 septembre 2020 - 09:35 |
vu que ce que te sort PDFVERSTEXTE cela m'étonnerait que ton pdf soit structuré. Un pdf structuré c'est par exemple un formulaire pdf à remplir.
Dans ton exemple 3 in n'y plus rien après 5,52 dans l'extraction de PDFVERSTEXTE ?
--
Ami calmant, J.P |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 16 septembre 2020 - 09:47 |
Non rien qui m'indique que c est la valeur à prendre .
J ai testé pdftotext.exe quand je tente de convertir un fichier PDF dans un fichier txt celui ci est entièrement vide . Aucune donnée |
| |
| |
| | | |
|
| | |
| |
Posté le 16 septembre 2020 - 11:25 |
Bonjour
J'ai eu aussi a me battre avec PDFversTexte récemment, et même en Windev25 ce n'est pas simple de restructuré le fichier obtenu
Quelques idées jetées comme ça:
Une chose, si vous passer votre PDF dans un convertisseur texte trouvable sur internet, est ce que celui ci est correcte à l'ouverture du fichier texte?
Vous pouvez aussi, aujourd'hui ouvrir directement votre PDF via une logiciel de traitement de texte ( sans faire de pub, je pense a Office2019 ou Office365 mais peut être aussi les suites en solution libre) Avez vous essayé afin de voir ce qu'il en est ? SI vous enregistrer ce fichier ouvert via un traitement de texte et que vous l'enregistrer en .txt , vos données sont elles mieux structurées? (le passage via Word a partir de Windev pourrait être une solution - pas propre mais efficace - d'obtenir un fichier texte exploitable par Windev ensuite- Convertir le PDF via Word (ou autre) via Windev, enregistrer le fichier en .TXT et le lire ensuite par WIndev La gestion de Word par Windev est ancienne et fonctionne bien - pour ce que je l'ai utilisée sur des versions anciennes de Word (jusqu'au 2016, je n'ai pas testé sur les dernière versions)
Une autre solution serait peut être de remplacer chaque retour chariot (RC) par une tabulation (TAB) et d'extraire la chaîne de caractère voulue en fonction de sa position... ainsi peu importe si votre fichier texte est d'une structure ou d'une autre, vous aurez les positions - à vous de savoir à quoi elles correspondent (ne pas hésiter a faire un TRACE afin de visualiser , je m'en suis sorti comem ça)-On peut supposer que ce sont des résultats d'examen ou de test et que la structure est constante, ce qui varie c'est le nombre d'information affichée - encore une fois c'est moche et usine a gaz mais ça peut résoudre votre problème le temps de trouver une belle solution
Sinon en effet passer par les expressions régulières - ce qui serait le plus propre, mais il faut quand même connaitre la structure de votre fichier texte: qu'est ce qui s'affiche et ou (sa position) |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 16 septembre 2020 - 11:58 |
J ai tout essayé en fait . La copie j y ai pensé mais j'ai des caractères spéciaux avec la bonne version d'office.
La conversion aussi .
Malheureusement pour la position c est impossible car je peux avoir d autres bilans sur mes résultats. hémogramme etc..... Donc la postion varie.
Si je n avais pas ces alignements de valeur j aurai pu m'en sortir.
Je pense que ces pdfs sont malheureusement mal structurés et je vais devoir passer par une saisie des données sniffff.
Merci encore pour toutes vos réponses .
Je vais continuer à batailler aussi sourire . |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 16 septembre 2020 - 12:53 |
Par contre quand je fais la conversion en xls il m importe bien les données et correctement dans chaque cellule.
J ai fait cette conversion par internet .
Dommage que je ne puisse pas faire une copie du fichier pdf |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 16 septembre 2020 - 14:27 |
A savoir pour la version 25 J ai telechargé la version express windev 25 et la fonction pdfDocument apporte effectivement plus d'améliorations . |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 16 septembre 2020 - 14:38 |
Et la fonction PDFversTexte est nettement mieux aussi |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
9 messages |
|
Posté le 16 septembre 2020 - 15:03 |
L'idéal aurait été que l'on dispose d'un pdf exemple.
Ca serait bien qu'on puisse partager des fichiers sur ce forum, dans certains cas, c'est indispensable...
--
Rémy BISSON
Gestélia INFORMATIQUE |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
962 messages
Popularité : +183 (185 votes) |
|
Posté le 16 septembre 2020 - 15:14 |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 16 septembre 2020 - 15:20 |
Tant que je suis là . Y a t-il une fonction qui permettrait de copier du texte ,stocké dans une variable, dans un fichier excel ou word?
Merci |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
1 623 messages
Popularité : +100 (114 votes) |
|
Posté le 16 septembre 2020 - 15:34 |
Malheureusement ya pas de miracles possibles.
Il va falloir trouver des astuces, repérer des similitudes etc etc
Nous le faisons en interne pour les factures fournisseurs, on a du mettre un outil de controle avant import pour verifier que tout a bien été trouvé car ce n'est pas toujours le cas. (la moindre petite exception fout en l'air la détection d'autres éléments) |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 16 septembre 2020 - 16:05 |
Oui il va falloir être méticuleux .
Je vais demander à PCSOFT de m'offrir la version 25 hihihihihi
C est frustrant de savoir qu il y a une autre amélioration . Mon projet ou mon idée est HS sans cette méthode . Le but est de tout extraire sans devoir faire de saisie. |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
962 messages
Popularité : +183 (185 votes) |
|
Posté le 17 septembre 2020 - 08:18 |
hello,
voici quelques questions concernant les documents à analyser :
1 - Est-ce qu'il y a le nom du labo dans le texte extrait ?
Si oui on pourrait faire :
a - Détection du Labo
b - Traitement différent suivant le labo
2 - Est-ce que le texte extrait se présente toujours de la même façon suivant le même Labo ?
3 - Dans ce cas l'info désirée est-elle toujours à la même place (par exemple toujours le xième nombre) ?
3 - Est-ce que tu ne veux extraire que les valeurs de TSH ?
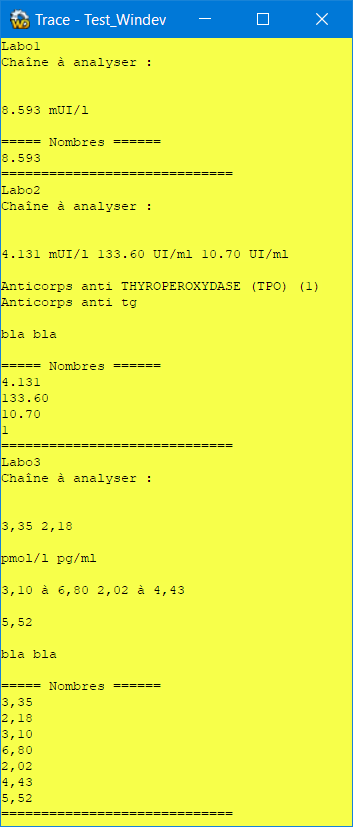
Voici un exemple d'utilisation des expressions régulières pour capturer tous les nombres après la ligne TSH dans tes 3 exemples:
les 3 exemples :
Labo1 est une chaîne = [
blabla
blabla
blabla
TSH 3ème génération (1)
8.593 mUI/l
fin
bla bla
]
Labo2 est une chaîne = [
blablabla
TSH 3ème génération (1)
4.131 mUI/l 133.60 UI/ml 10.70 UI/ml
Anticorps anti THYROPEROXYDASE (TPO) (1)
Anticorps anti tg
bla bla
fin
]
Labo3 est une chaîne = [
bla
bla
TSH 3ème génération (1)
3,35 2,18
pmol/l pg/ml
3,10 à 6,80 2,02 à 4,43
5,52
bla bla
fin
]
=============================================================
Le code :
tsh,FiltreNombre,FiltreTsh,ChaineTsh sont des chaînes
RxMatches est un MatchCollection dynamique
monGroupe est un GroupCollection dynamique
TableauLabos est un tableau de chaînes = ["Labo1","Labo2","Labo3"]
FiltreTsh = "TSH 3ème génération \(1\)(.*)fin"
POUR TOUT labo de TableauLabos
RxMatches = Regex.Matches({labo},FiltreTsh,RegexOptions.Singleline)
POUR TOUT clMatch de RxMatches
monGroupe = clMatch.Groups
ChaineTsh = monGroupe.get_Item(1).Value
FIN
FiltreNombre = "\d+([.,]+\d+)?"
Trace(labo)
Trace("Chaîne à analyser :")
Trace(ChaineTsh)
Trace("===== Nombres ======")
RxMatches = Regex.Matches(ChaineTsh,FiltreNombre,RegexOptions.Singleline)
POUR TOUT clMatch de RxMatches
Trace(clMatch.value)
FIN
Trace("=============================")
FIN
Le moteur d'expressions régulières utilisé est celui de dotnet car plus complet que celui de windev. Pour pouvoir l'utiliser dans windev : Atelier/.NET/Utiliser un assemblage choisir System
Le résultat :
--
Ami calmant, J.P |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 17 septembre 2020 - 10:52 |
Bonjour et merci pour ce message . Je vais analyser le code .
En ce qui concerne la position je peux laisser tomber car parfois sur une même feuille je peux avoir aussi un hémogramme donc ça change la position de mes champs . TSH , T3, T4 , anti tpo etc...... (le bilan thyroïdien complet ou pas)
Je vais tenter d'insérer des images pour quelques exemples |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 17 septembre 2020 - 11:02 |
Exemple 1 où je n ai que le bilan thyroidien avec seulement la tsh

|
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 17 septembre 2020 - 11:05 |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 17 septembre 2020 - 11:08 |
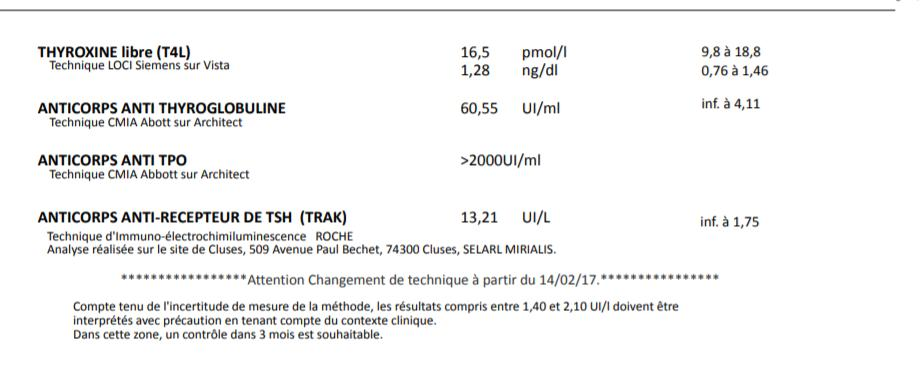
2 eme page qui présente les analyses de la thyroide
|
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 17 septembre 2020 - 11:22 |
Je tenais à dire que ces analyses m'appartiennent ........
Sur ces analyses je cherche à extraire la TSH , T3 , T4 , anticorps anti thyroglobuline, anticorps anti tpo et anticorps anti recepteur de TSH
Parfois je n ai que la TSH
Parfois TSH + T3 + T4
OU TSH avec les anticorps
Ca ce n est pas un souci
mais la fonction pdfVERSTEXTE peut me sortir 3 valeurs alignées sans savoir à quoi cela correspond comme l exemple ci dessous : je peux avoir
T4
16.5 >20000 60.55
Anticorps anti THYROPEROXYDASE (TPO) (1)
Anticorps anti tg
Comme on peut le voir sur le bilan 16.4 correspond à la T4
>20000 au Anticorps anti THYROPEROXYDASE (TPO) (1)
60.55 Anticorps anti tg
pas d indicateur........
et parfois tout est bien aligné quand je n ai que la TSH
Pour le moment je n'ai qu'un labo |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 17 septembre 2020 - 11:35 |
La fonction pdfverstexte dans la version 25(Express) est plus propre . J ai des retour à la ligne certes mais mes données se suivent . Ca se gère |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 17 septembre 2020 - 13:00 |
TSH 3ème génération (1)<TAB>(Technique LOCI Siemens sur Vista)<TAB><TAB>4.131 mUI/l 133.60 UI/ml 10.70 UI/ml<TAB><TAB>14-02-2018 8.593<TAB><TAB>Anticorps anti THYROPEROXYDASE (TPO) (1)<TAB>(Technique CMIA Abbott sur Architect)<TAB><TAB>(<5.60)<TAB><TAB>Anticorps anti THYROGLOBULINE (TG) (1)<TAB>(Technique CMIA Abbott sur Architect)<TAB><TAB>(<4.10)<TAB><TAB>Page 2<TAB><TAB>/4<TAB><TAB>Dossier validé
Voilà un exemple . Chaine extraite ......... J ai remplacé les retours chariots par des TAB
3 valeurs alignées 4.131 mUI/l 133.60 UI/ml 10.70 UI/ml
4.131 mUI/l correspond à la TSH
133.60 UI/ml correspond à Anticorps anti THYROPEROXYDASE (TPO)
10.70 UI/ml correspond à Anticorps anti THYROGLOBULINE (TG) (1) |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
962 messages
Popularité : +183 (185 votes) |
|
Posté le 18 septembre 2020 - 08:17 |
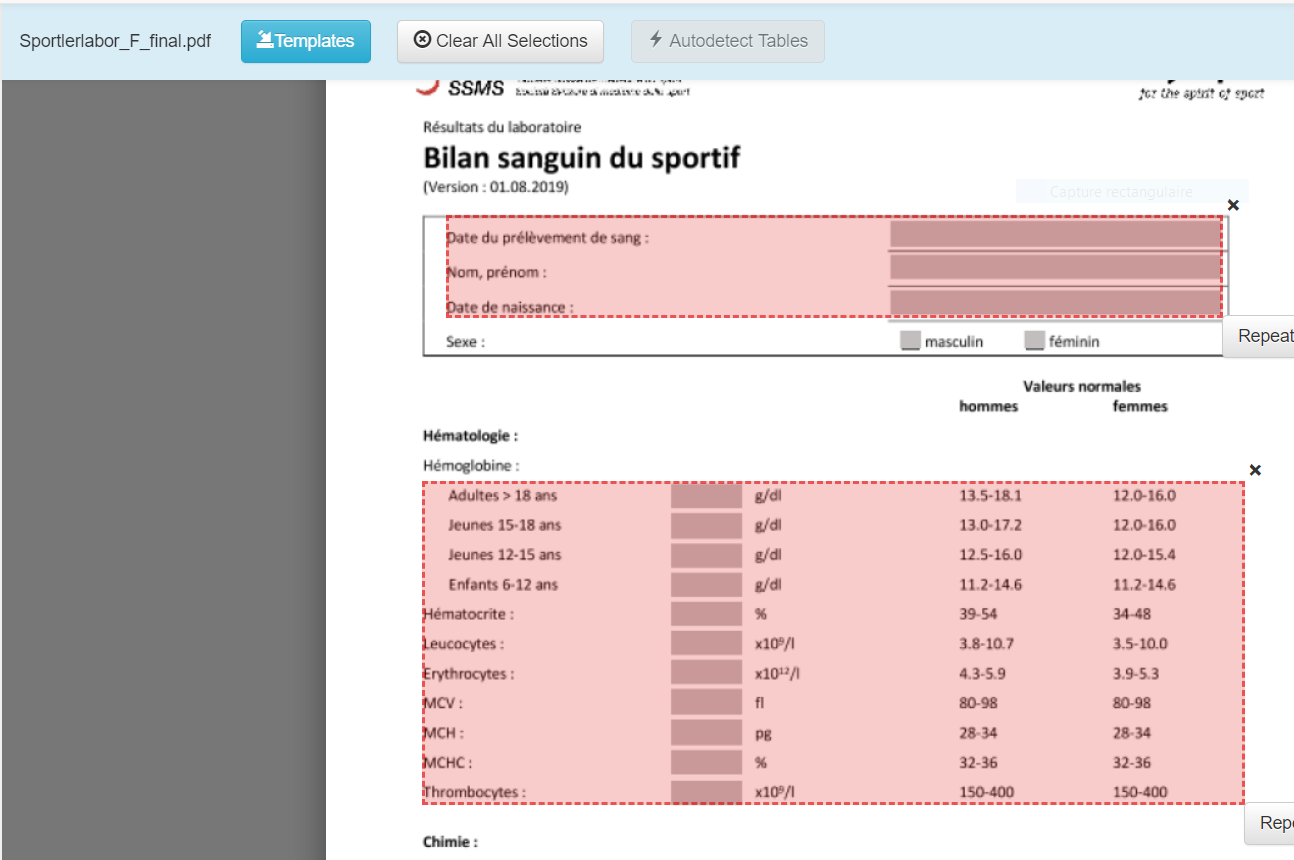
hello,
comme les données de tes PDF semblent structurées tu devrais essayer le logiciel tabula de licence MIT (opensource) ici :
https://tabula.technology/
--
Ami calmant, J.P |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 18 septembre 2020 - 09:44 |
Ca fonctionnne .....
En fait je vais proposer cette appli à une personne qui reçoit directement les fichiers pdf via un serveur .
Le but est, lors de l'ouverture d'un pdf, d'extraire les données sans avoir à faire de manip .
Merci pour cette solution . Elle me servira certainement . |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 18 septembre 2020 - 09:47 |
je pourrais lui demander de faire une manip avec un convertisseur de texte mais directement via l'appli sans devoir la quitter. |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
962 messages
Popularité : +183 (185 votes) |
|
Posté le 18 septembre 2020 - 10:16 |
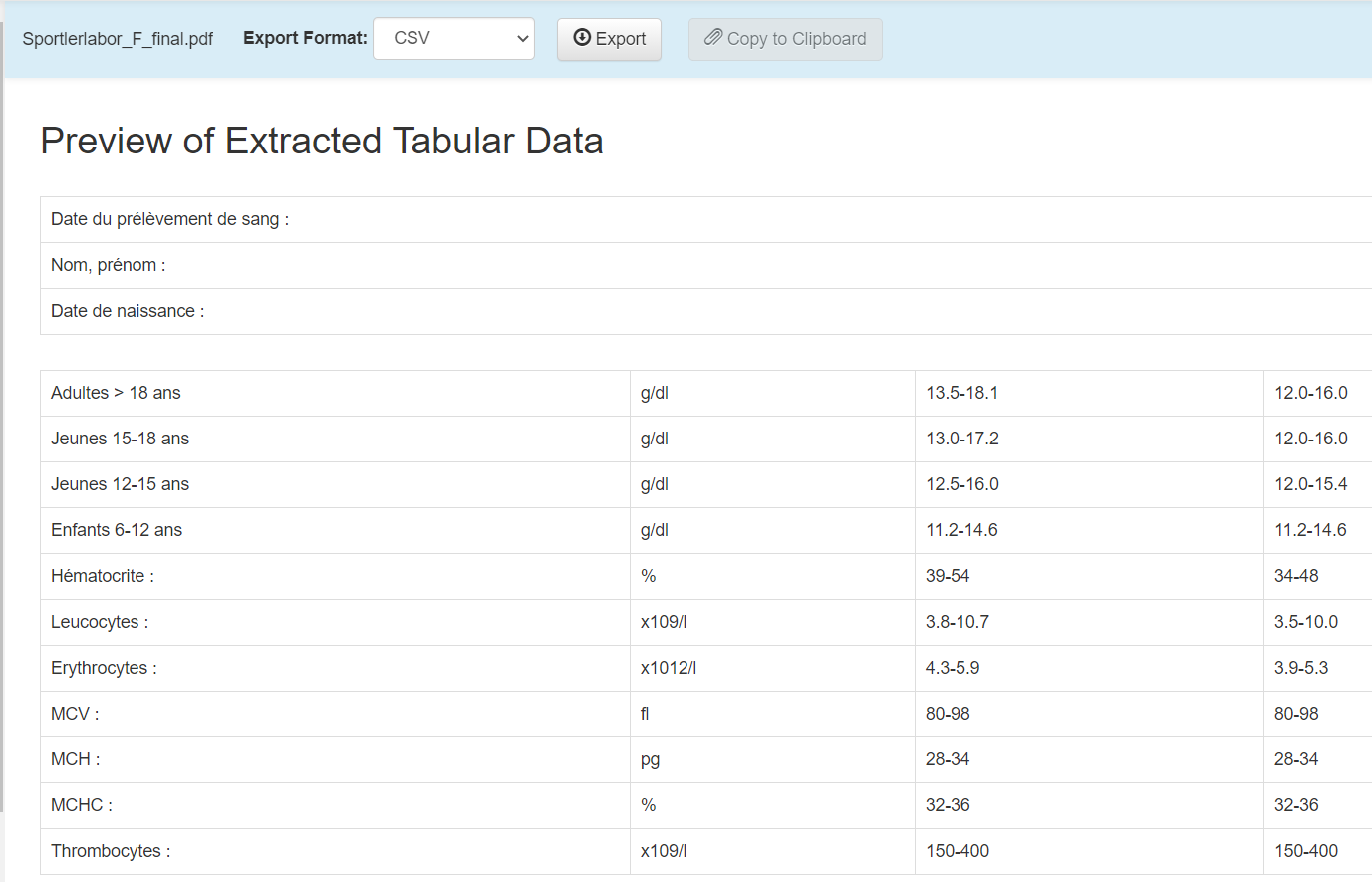
l'appli existe aussi en mode ligne de commande exemple :
java -jar tabula-1.0.3-jar-with-dependencies.jar M:\temp\Sportlerlabor_F_final.pdf --area %30,0,60,100 -o bilan.csv
le paramètre --area permet de définir la zone de la page à extraire top,left,bottom,right . Dans mon exemple j'extrait la partie qui commence à 30% en hauteur jusqu'à 60% en hauteur.
Résultat bilan.csv :
Hématologie :,,,
Hémoglobine :,,,
Adultes > 18 ans,g/dl,13.5-18.1,12.0-16.0
Jeunes 15-18 ans,g/dl,13.0-17.2,12.0-16.0
Jeunes 12-15 ans,g/dl,12.5-16.0,12.0-15.4
Enfants 6-12 ans,g/dl,11.2-14.6,11.2-14.6
Hématocrite :,%,39-54,34-48
Leucocytes :,x109/l,3.8-10.7,3.5-10.0
Erythrocytes :,x1012/l,4.3-5.9,3.9-5.3
MCV :,fl,80-98,80-98
MCH :,pg,28-34,28-34
MCHC :,%,32-36,32-36
Thrombocytes :,x109/l,150-400,150-400
Attention si il y a des , dans le texte des PDF
--
Ami calmant, J.P |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 18 septembre 2020 - 10:34 |
là suis un peu perdu ..... Je peux integrer ce code dans Windev? |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
962 messages
Popularité : +183 (185 votes) |
|
Posté le 18 septembre 2020 - 12:59 |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 18 septembre 2020 - 16:02 |
C est magique ça fonctionne .... Et bravo pour ce code. Le souci c est que je n'ai qu'une partie de l'examen . Même en changeant mes valeurs d area je n arrive pas à tout avoir .
Me faudrait il juste une seule page? Car l'examen que j ai extrait contient 2 pages et il finit par me générer une erreur |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
962 messages
Popularité : +183 (185 votes) |
|
Posté le 18 septembre 2020 - 16:31 |
pour spécifier le nombre de pages il faut rajouter l'option --page dans la ligne de commande sinon il n'y a que la première page extraite
exemple :
--page all toutes les pages
--page 1-2 les pages 1 à 2
--
Ami calmant, J.P |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 18 septembre 2020 - 17:49 |
Problème résolu . Un grand merci pour ce code J.P et pour toutes ces réponses ......... |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 18 septembre 2020 - 18:17 |
Par contre dans ma ligne de commande je suis obligée de mettre en dur le chemin du fichier ?
Je tente de remplacer mon chemin par une variable et j ai souci avec les doubles quotes |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 18 septembre 2020 - 19:16 |
MaCommande est une chaîne = "java -jar ""C:\Mes projets\MonMDPP\exe\tabula-1.0.3-jar-with-dependencies.jar"" "+sFichier+" "" --page all"
fichier introuvable |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 18 septembre 2020 - 19:20 |
C est ok j avais oublié une double quote
Grand merci |
| |
| |
| | | |
|
| | |