| |
Membre enregistré
31 messages |
|
Posté le 28 septembre 2020 - 14:19 |
Bonjour à tous,
L'un de nos client souhaite afficher dans une table 85.000 enregistrements et pouvoir ajouter des filtres sur celle-ci.
Après avoir essayé de mille façon différentes, je me heurte à un mur. Je vous explique mes différente démarche.
Pour le test, toutes les membre de mon analyse sont en clé/clé avec doublon.
J'ai essayé avec une table avec fichier à accès direct et dans ma procédure de filtre je créer une clé de parcourt que j'utilise ensuite dans un HFIltre():
Avantage :
- Temps de charge rapide (moins de 20ms pour afficher les 85.000 enregistrement)
- Temps des filtres rapides (200ms)
- Ne surcharge pas le réseau
Inconvénient ::
- Si le client tente de trié la table, tout est ralentie
Affichage
Scrolling
Logiciel plante si le client reclic sur la table
J'ai ensuite essayé avec une table fichier avec fichier charger en mémoire. Tous allez même si les temps été relativement long mais cette solution surcharger le réseau et devait très lent au bout de quelques heures (25 postes utilise la requête en simultané pour raméner les 85.000 enregistrements et cela plusieurs fois dans l'heure)
Autre solution, j'ai utilisé une table mémoir sur une requête mais je retrouve à la situation précédente.
Est-il possible de switcher entre Mémoir et Accès direct en programation ?
J'ai aussi tenté l'expérience avec une analyse Client/Serveur mais pas de changement probant.
Si quelqu'un à déjà eu se genre de problème et l'a solutionné de quelconque manière je suis à l'écoute.
Bien à vous, Benjamin. |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
3 889 messages
Popularité : +227 (347 votes) |
|
Posté le 28 septembre 2020 - 15:23 |
Bonjour,
Pourquoi ne pas filtrer en amont via une requête paramétrée.
Le client désire-t-il vraiment les 85.000 tuples, ou désire-t-il faire des recherche sur ces tuples et avoir le résultat ?
--
Il y a peut être plus simple, mais, ça tourne |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
3 889 messages
Popularité : +227 (347 votes) |
|
Posté le 28 septembre 2020 - 15:28 |
S'il désire vraiment voir apparaître les 85000 lignes, c'est un surhomme au niveau de la lecture et du traitement. A raison d'une ligne lue (et traitée) toute les 1/2 seconde, il faut près de 12h00 pour faire le boulot.
--
Il y a peut être plus simple, mais, ça tourne |
| |
| |
| | | |
|
| | |
| |
Posté le 28 septembre 2020 - 15:52 |
Bonjour,
Une idée peux être vous aider pour résoudre le problème de lentement : un système de pagination pour afficher x lignes dans la table avec une requête paramétré ?!
Bonne developpement |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 574 messages
Popularité : +222 (260 votes) |
|
Posté le 28 septembre 2020 - 20:51 |
@Benjamin L. : Windev n'est pas fait pour ça. Ca fait longtemps que je milite pour que le framework soit grandement amélioré notamment en terme de rapidité d'exécution. J'ai exactement les mêmes problèmes avec moins d'enregistrement.
@Voroltinquo:
S'il désire vraiment voir apparaître les 85000 lignes, c'est un surhomme au niveau de la lecture et du traitement. A raison d'une ligne lue (et traitée) toute les 1/2 seconde, il faut près de 12h00 pour faire le boulot.
Je ne suis pas d'accord avec toi. Avoir une liste de 10 000 enregistrements est tout à fait légitime. Nos clients aiment pouvoir trier leurs données comme ils l'entendent sans avoir à faire de filtre préalable. Mais admettons qu'on parte sur ton principe, je veux voir tous mes articles triés par marge.
Je fais une requête que j'affiche dans une table. Temps d'affichage total 3 à 5 secondes selon le nombre de colonnes à afficher...
Bref c'est lent et c'est ce que reproche Benjamin...
--
Cordialement,
Philippe SAINT-BERTIN |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 29 septembre 2020 - 00:28 |
Voroltinquo a écrit :
> S'il désire vraiment voir apparaître les 85000 lignes, c'est un surhomme au niveau de la lecture et du traitement. A raison d'une ligne lue (et traitée) toute les 1/2 seconde, il faut près de 12h00 pour faire le boulot.
La n'est pas la question comme le dit @Philippe SB, il n'y aurait que moi, je n'afficherais que le résultat de la requête.Testeur a écrit :
Bonjour,
Une idée peux être vous aider pour résoudre le problème de lentement : un système de pagination pour afficher x lignes dans la table avec une requête paramétré ?!
Malheureusement, cela ne convient pas a ma demande, il faut tout sur une et une seul page. |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
129 messages
Popularité : +20 (20 votes) |
|
Posté le 29 septembre 2020 - 09:17 |
Bonjour Benjamin,
Pour ma part j'utilise des tables remplissage Fichier / Requête en accès direct sur des fichiers très volumineux (base HFSQL) sans souci de lenteur particulier.
Cela plante chez vous dès que vous triez une colonne même sans application de filtre ?
Si oui avez-vous mis du code dans le traitement Affichage d'une ligne de votre table ?
Si les lenteurs sont consécutifs aux filtres, avez-vous essayé de lancer une nouvelle requête d'affichage en prenant en compte ces filtres ?
Un exemple : vous avez un fichier dossier et une requête RQT_recherche_dossier renvoyant les mêmes rubriques mais avec des paramètres dans la clause WHERE
Vous créez la table TABLE_dossier à partir du fichier dossier, les propriétés de tri / recherche se mettent automatiquement en place en fonction des index de table
i est un entier
champ est une chaîne
avecRecherche est un booléen
i = 1
champ = EnumèreChamp( GR_filtres, i )
TANTQUE champ <> ""
i++
SI SansEspace( { champ, indChamp } ) <> "" ET { champ, indChamp }..Visible ALORS avecRecherche = Vrai
champ = EnumèreChamp( GR_filtres, i )
FIN
SI INT_IJ <> -1 ALORS avecRecherche = Vrai
SI INT_IJ_base <> -1 ALORS avecRecherche = Vrai
SI INT_rente <> -1 ALORS avecRecherche = Vrai
SI avecRecherche ALORS
RQT_recherche_dossier._IDDossier_qualification_niveau1 = COMBO_dossier_qualification_niveau1
RQT_recherche_dossier._IDDossier_qualification_niveau2 = COMBO_dossier_qualification_niveau2
RQT_recherche_dossier._IDDossier_type = COMBO_dossier_type
RQT_recherche_dossier._IDDossier_etat = COMBO_dossier_etat
SELON COMBO_date
CAS "DateReception" :
RQT_recherche_dossier._dateReception_debut = SAI_date_debut
RQT_recherche_dossier._dateReception_fin = SAI_date_fin
RQT_recherche_dossier._dateEvenement_debut = Null
RQT_recherche_dossier._dateEvenement_fin = Null
CAS "DateEvenement" :
RQT_recherche_dossier._dateReception_debut = Null
RQT_recherche_dossier._dateReception_fin = Null
RQT_recherche_dossier._dateEvenement_debut = SAI_date_debut
RQT_recherche_dossier._dateEvenement_fin = SAI_date_fin
AUTRE CAS :
RQT_recherche_dossier._dateReception_debut = Null
RQT_recherche_dossier._dateReception_fin = Null
RQT_recherche_dossier._dateEvenement_debut = Null
RQT_recherche_dossier._dateEvenement_fin = Null
FIN
RQT_recherche_dossier._utilisateurAffecte = COMBO_utilisateurAffecte
SI INT_IJ <> -1 ALORS RQT_recherche_dossier._IJ = INT_IJ
SI INT_IJ_base <> -1 ALORS RQT_recherche_dossier._IJ_base = INT_IJ_base
SI INT_rente <> -1 ALORS RQT_recherche_dossier._rente = INT_rente
HExécuteRequête( RQT_recherche_dossier )
HLitPremier( RQT_recherche_dossier )
TABLE_dossier..FichierParcouru = RQT_recherche_dossier
SINON
TABLE_dossier..FichierParcouru = dossier
TableAffiche( TABLE_dossier, taInit )
FIN
Si vous êtes obligé d'avoir un code de calcul ou de formatage dans la partie traitement Affichage d'une ligne de votre table, une solution serait de pré-filtrer la table pour avoir un premier jeu d'informations les plus pertinentes (plage de dates sur le mois ou l'année courante, booléen à traiter, etc.) |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
159 messages
Popularité : +0 (2 votes) |
|
Posté le 29 septembre 2020 - 09:20 |
Bonjour,
Petite précision car cela n'est pas très clair : la base est sur un serveur et en ClientServeur ou bien en HF Classique ?
Et si ce n'était pas du windev et des fichiers HF mais une base Postgresql ou autre vous feriez comment ?
Déjà les données font quelle taille pour 85000 lignes ? Un essai avec excel pour voir ?
La base est mise à jour/modifiée en temps réel tous les combien ? car on peut peut-être la rapatrier en local périodiquement ?
Suivant le type d'interrogation demandé on peut aussi essayer de modifier la structure des données ? |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 574 messages
Popularité : +222 (260 votes) |
|
Posté le 29 septembre 2020 - 12:10 |
@Julien V
Pour ma part j'utilise des tables remplissage Fichier / Requête en accès direct sur des fichiers très volumineux (base HFSQL) sans souci de lenteur particulier.
J'utilise une table fichier avec PostgreSQL et je constate les même problèmes que Benjamin. Je précise que j'utilise l'accès natif.
@BP
Et si ce n'était pas du windev et des fichiers HF mais une base Postgresql ou autre vous feriez comment ?
de la même manière qu'avec HFSQL en utilisant l'accès natif
Déjà les données font quelle taille pour 85000 lignes ? Un essai avec excel pour voir ?
Aucun rapport
Suivant le type d'interrogation demandé on peut aussi essayer de modifier la structure des données ?
Le problème ne vient pas de l'interrogation des données, mais de la lenteur de l'affichage par Windev...
--
Cordialement,
Philippe SAINT-BERTIN |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 574 messages
Popularité : +222 (260 votes) |
|
Posté le 29 septembre 2020 - 12:28 |
Exemple concret:
Table fichier direct avec 11 000 articles:
Trie sur le code: 12 secondes
Si quelqu'un a une explication je suis preneur...
--
Cordialement,
Philippe SAINT-BERTIN |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 29 septembre 2020 - 13:14 |
Hello tout le monde,
pour le moment la seule solution viable que j'ai trouver mais qui possède quelques bugs par-ci, par-là et d'utiliser un accès direct et de switcher sur un HFiltre via les champs de saisie de filtre, la vitesse est correct mais si l'utilisateur décide de filtrer via la FAA de Windev des tables, tout expose et les lenteurs ce font ressentir instantanément.
Je vous link une vidéo pour vous montrer le résultat :
|
| |
| |
| | | |
|
| | |
| |
Posté le 29 septembre 2020 - 18:02 |
Bonjour.
Peut-etre une idée ..
Pour mes application, j'ai développé un composant, qui en gros.
1) recoit en entrée, un SQL
2) Affiche une table, présentant les données
3) Affiche aussi un systeme de filtres multi lignes, pour chaque colonne, qui s'adapte (avec un assistant) selon le type de colonne.
Comme le SQL peut ramener pas mal de lignes, j'ai ajouté la possibilité d'ajouter au SQL initial une clause SQL Top (parametrable, pour chaque SQL et pour chaque usager)
Cette clause Top est éliminée des qu'on commence a définir un filtre.
Ca permet aux usagers d'avoir un échantillon des données, ce qui les aident a définir des filtres pertinents.
Ils peuvent décider de debrayer le TOP, mais dans ce cas, ce sont eux qui décident du temps d'attente.
J'ai aussi joué avec le fait de rentre la table visible, le temps de la charger en données. Mais je ne sais pas si cela peut avoir une influence sur la vitesse
Bonne journée.
Michel Lahellec, Montreal |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
3 889 messages
Popularité : +227 (347 votes) |
|
Posté le 29 septembre 2020 - 20:14 |
Une solution alternative consisterait à utiliser une rupture sur champ table (sur la colonne la plus représentative pour le client) avec affichage différé.
--
Il y a peut être plus simple, mais, ça tourne |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 574 messages
Popularité : +222 (260 votes) |
|
Posté le 01 octobre 2020 - 08:09 |
Je viens de me rendre compte que l'image que j'ai postée apparait comme un pins alors qu'elle a une taille tout à fait normale en vrai, surement un bug lors de l'import des images sur le forum...
Bref dans mon cas, j'ai tracé les requêtes envoyées par windev au moteur Postgresql et j'ai pu observer un certain nombre de choses. Tout d'abord des requêtes mal orthographiées qui sont donc en erreur, et quelques 230 requêtes lors du tri sur la colonne définie comme clé unique dans la table.
J'ai donc fait un test, j'ai mis la colonne comme clé avec doublon et là miracle, le tri se fait en moins d'une seconde contre 12 auparavant. Donc lorsqu'une colonne est définie comme clé unique sur une base autre que HFSQL et avec l'accès natif, Windev envoie un certains nombre de requêtes avec une limite à 100 enregistrements pour faire un fetch. Mais comme il récupère tous les enregistrements, ça n'a plus aucun sens car pour 10000 enregistrements il fait 100 requêtes car à chaque requête. Une surcharge du serveur inutile à mon avis.
Voici ce qu'on retrouve dans les logs
LOG: n'a pas pu recevoir les données du client : unrecognized winsock error 10054
ERREUR: la syntaxe LIMIT #,# n'est pas supportée au caractère 1788
Il serait temps de faire évoluer l'accès natif et les méthodes de récupération...
Pour essayer d'aller plus vite, j'ai voulu faire un tableau de classe mais le remplissage du tableau met entre 3 et 5 secondes. Là aussi une amélioration du framework serait vraiment bien.
--
Cordialement,
Philippe SAINT-BERTIN |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
202 messages
Popularité : +6 (6 votes) |
|
Posté le 01 octobre 2020 - 12:12 |
Un petit truc que j'utilise lors du remplissage d'une table (et pourquoi pas du coup lors des tris/filtres etc) c'est de la passer en matable..affichageactif=faux avant puis la repasser à vrai ensuite. Ca a une influence importante sur le temps de remplissage, et ça évite aussi des effets assez moche de clignotements et autre pendant le remplissage. |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
190 messages
Popularité : +12 (12 votes) |
|
Posté le 01 octobre 2020 - 17:41 |
Bonjour
Sur ce sujet récurrent je répète que pour ma part avec MySql/MariaDb, moteur InnoDB, en accès natif , du SQLExec avec la requête précise (et non du databinding sur des tableaux d'objets incluant tous les champs de la table SQL, une hérésie pour moi !) limitée au nombre de colonnes affichée, une table mémoire non reliée, j'obtiens des performances tout à fait acceptable même autour de 80000 lignes et que les tris , qui ne gérèrent donc pas de requêtes supplémentaires, sont quasi instantanés.
Je rappelle aussi que pour limiter le trafic réseau inutile je place par défaut un LIMIT 50 que l'utilisateur peut modifier s'il souhaite vraiment récupérer toute les lignes, ce qui n'est vraiment pas le cas le plus fréquent. Mais donc au moins à l'arrivée sur la table sans n'avoir mis aucun critère il ne visualise que les 50 premières lignes.
Quant à ceux qui nous disent qu'il faut absolument tout voir dans la table, que c'est une exigence du client etc... Comment dire...
J'aimerais bien savoir ce que vous ferez quand vos tables ne seront plus dans les 100 000 lignes mais plutôt dans les millions de lignes ...
Si la simple logique ne suffit pas à vous convaincre (elle devrait pourtant !) ayez une pensée écologique pour la planète et limitez les transferts de données inutiles.
--
Côme, Clairinfo |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 574 messages
Popularité : +222 (260 votes) |
|
Posté le 01 octobre 2020 - 20:26 |
Nous n'avons pas tous les mêmes exigences. Si attendre 5 a 10 secondes pour afficher des données te semble normal, moi non pas avec le matériel et la puissance des pc aujourd'hui.
Qu'entends tu par "j'obtiens des performances tout à fait acceptable même autour de 80000 lignes" ?
--
Cordialement,
Philippe SAINT-BERTIN |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
190 messages
Popularité : +12 (12 votes) |
|
Posté le 01 octobre 2020 - 21:26 |
Salut
Test à l'instant sur une base de test (serveur local par contre, ce serait plus long évidemment selon le réseau mais si le but est de mesurer le remplissage d'une table mémoire le test est intéressant non ?)
Chargement de 63 609 ligne issue d'une requête SQL en 1,7 seconde (les lignes contiennent ici 16 colonnes dont des notes.)
On peut sûrement obtenir mieux avec d'autres technos mais franchement je trouve que c'est acceptable pour une application de gestion.
Je peux te montrer cela en teamviewer si tu le souhaites.
Voilà la requête SQL testée :
SELECT T1.NoDossier,T1.CodeAdh,T2.Nom,T2.Prenom,T3.NomSite,T1.DateEnr,T1.CodeUser,T1.Annee,T1.Etat,T1.Solde,T1.CodeStat,T1.TypeDoss,T1.ResaEnCours,T1.NoteDossier,T1.MailBilletterie,T1.MailAgent,T1.DossierDetail,T4.Couleur FROM 01doss T1 LEFT JOIN 01adh T2 ON (T1.CodeAdh = T2.CodeAdh) LEFT JOIN 01site T3 ON (T1.NoSite = T3.NoSite) LEFT JOIN 01doss_stat T4 ON (T1.CodeStat = T4.CodeStat) ORDER BY T1.DateEnr DESC,T1.NoDossier DESC
--
Côme, Clairinfo |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
190 messages
Popularité : +12 (12 votes) |
|
Posté le 01 octobre 2020 - 21:54 |
Plus précisément en retirant le temps d'exécution de la requête, le chargement de la table mémoire prend ici 1.4 seconde pour les 63 609 lignes.
--
Côme, Clairinfo |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
190 messages
Popularité : +12 (12 votes) |
|
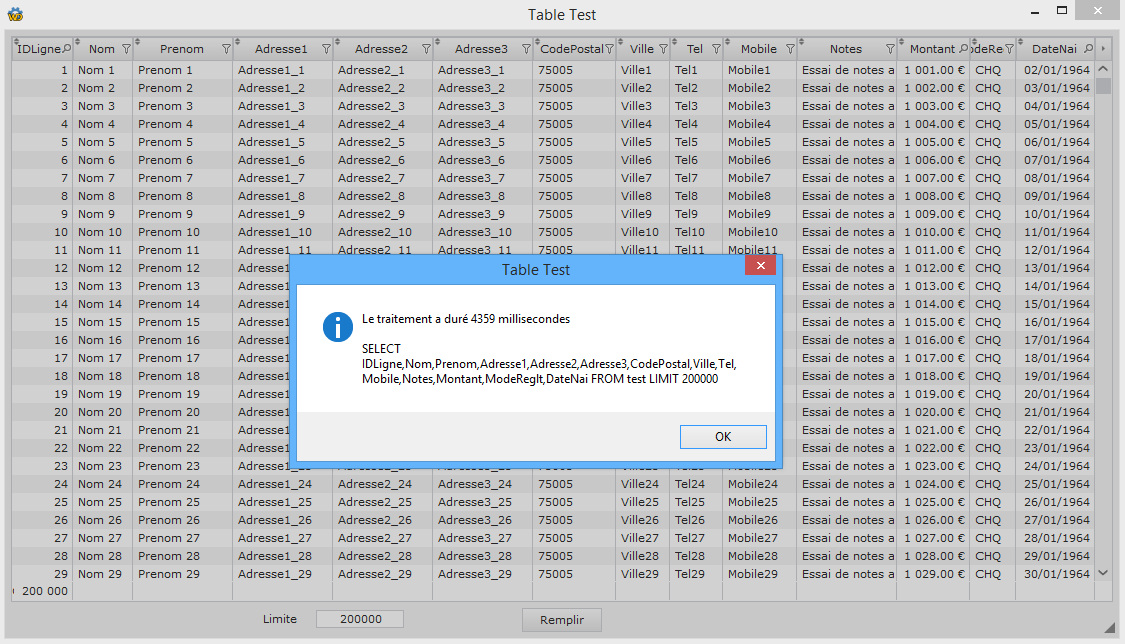
Posté le 02 octobre 2020 - 01:49 |
Bon j'ai monté un petit jeu de test et voilà les résultats que je trouve "acceptables"
Ici on a 14 colonnes remplies de textes, dates, nombres
85000 records => 1.9 s
100000 records => 2.2 s
150000 records => 3.3 s
200000 records => 4.4 s
Et bien sûr contrairement aux tables "fichiers" ici on a vraiment toutes les données dans la table au bout de ce délai. On peut les compter et les exporter immédiatement.
--
Côme, Clairinfo |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
190 messages
Popularité : +12 (12 votes) |
|
Posté le 02 octobre 2020 - 12:22 |
Bonjour
Elément de comparaison intéressant je trouve
Excel 2016 met plus de 6 secondes pour ouvrir un fichier xlsx contenant ces même 200 000 lignes
La table mémoire, en mode non relié, de windev s'en sort plutôt bien
Bonne journée à tous
--
Côme, Clairinfo |
| |
| |
| | | |
|
| | |
| |
Posté le 02 octobre 2020 - 14:55 |
perso, je fais :
1. grosse explication au client que c'est une très mauvaise idée. L'argument massue est que ca coutera BEAUCOUP plus cher à mettre en place que la solution avec filtre avant affichage.
S'il est vraiment idiot, j'implémente comme ca :
2. table lié au fichier SANS chargement en mémoire
3. suppression de toutes les FAA dans la table (pas de tri, rien)
4. ajout de controles au dessus de la table pour remplacer les faa par mon code
5. pour le tri, proposition uniquement des champs clés
6. pour le tri, changement de la propriété de la table pour la clé de parcours et réaffichage
7. pour les recherches/sélection utilisation des filtres
-SI- il y a des demandes qui ne peuvent pas être résolues avec les filtres et qui obligent à utiliser une requête
8. ajout d'une deuxième table normalement invisible basée sur la requête et avec exactement le même look/position
9. quand on est dans ce cas, la table fichier devient invisible, la table requete visible et on affiche les résultats dedans |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 574 messages
Popularité : +222 (260 votes) |
|
Posté le 02 octobre 2020 - 14:55 |
Remplir un tableau de classe de 200 000 enregisterments en c# met un peu plus d'1 seconde, Windev est 4 fois plus lent sans liaison je te laisse imaginer remplir ton tableau de classe et afficher la table...
Manque quand même de l'optimisation dans le framework c'est juste un fait.
--
Cordialement,
Philippe SAINT-BERTIN |
| |
| |
| | | |
|
| | |
| |
Posté le 02 octobre 2020 - 15:30 |
@SB
meme avec les instruction SQLTable ou FichierVersTableMémoire? |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
190 messages
Popularité : +12 (12 votes) |
|
Posté le 02 octobre 2020 - 16:36 |
Philippe SB a écrit :
Remplir un tableau de classe de 200 000 enregisterments en c# met un peu plus d'1 seconde, Windev est 4 fois plus lent sans liaison je te laisse imaginer remplir ton tableau de classe et afficher la table...>
Manque quand même de l'optimisation dans le framework c'est juste un fait.
Suis plutôt d'accord sur ce point et bien sûr tout n'est pas parfait dans windev.
Pour être honnête l'export Excel en FAA depuis la table mémoire sur l'exemple montré ici avec les 200 000 lignes ne va pas au bout chez moi, il tombe en erreur alors qu'il fonctionne à 150 000, je n'ai pas investigué plus que cela.
--
Côme, Clairinfo |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 574 messages
Popularité : +222 (260 votes) |
|
Posté le 02 octobre 2020 - 17:38 |
Pour être honnête l'export Excel en FAA depuis la table mémoire sur l'exemple montré ici avec les 200 000 lignes ne va pas au bout chez moi, il tombe en erreur alors qu'il fonctionne à 150 000, je n'ai pas investigué plus que cela.
On a eu le même problème depuis on limite les exports à 65 000 lignes. D'un autre côté c'est relativement rare qu'on exporte autant de données dans Excel.
--
Cordialement,
Philippe SAINT-BERTIN |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
47 messages
Popularité : +1 (1 vote) |
|
Posté le 02 octobre 2020 - 20:39 |
Salut Côme
tu remplis ta table avec des données aléatoires ou depuis un fichier ?
--
Maxime |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 574 messages
Popularité : +222 (260 votes) |
|
Posté le 02 octobre 2020 - 21:10 |
depuis une requête, c'était le but du test...
--
Cordialement,
Philippe SAINT-BERTIN |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 06 octobre 2020 - 16:25 |
Merci a tous pour vos réponses toutes plus intéressantes les unes que les autres.
Je continu d'investiger de mon coter pour obtenir de meilleurs résultats et reviens vers vous !
Cordialement Benjamin |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
1 144 messages
Popularité : +50 (142 votes) |
|
Posté le 06 octobre 2020 - 17:10 |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 574 messages
Popularité : +222 (260 votes) |
|
Posté le 06 octobre 2020 - 18:05 |
@THIERRY TILLIER
Dans ce genre de cas, est-ce q'une VUE n'améliorerait pas les choses ? Je n'ai pas testé, je pose juste la question.
perso j'ai fait le test mais les temps de réponse restent les mêmes. la seule différence c'est que tout est chargé en mémoire donc une fois que tout est là tu peux faire ce que tu veux mais ça peut être long.
--
Cordialement,
Philippe SAINT-BERTIN |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 13 octobre 2020 - 11:08 |
Philippe SB a écrit :
perso j'ai fait le test mais les temps de réponse restent les mêmes. la seule différence c'est que tout est chargé en mémoire donc une fois que tout est là tu peux faire ce que tu veux mais ça peut être long. -- Cordialement, Philippe SAINT-BERTIN
Et dans le cas ou un utilisateur souhaite actualiser les changements, tu est dans l'obligation de tous recaharger, et donc potentiellement de surcharger les réseaux, pour le moment je me heurte à un mur qui me semble insurmontable.
Bien à vous, Benjamin |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 574 messages
Popularité : +222 (260 votes) |
|
Posté le 13 octobre 2020 - 11:13 |
Et dans le cas ou un utilisateur souhaite actualiser les changements, tu est dans l'obligation de tous recaharger, et donc potentiellement de surcharger les réseaux, pour le moment je me heurte à un mur qui me semble insurmontable.
Tant que PC Soft ne rendra pas les choses plus rapides, il n'y a aucune solution simple.
Tu travailles sur quel SGBD ?
--
Cordialement,
Philippe SAINT-BERTIN |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
35 messages
Popularité : +2 (2 votes) |
|
Posté le 13 octobre 2020 - 11:53 |
Bonjour,
Un client qui a besoin des 200 000 enregistrements et qu'il veut faire des TCD ou graph dessus, c'est pas juste pour avoir un XLS.
Ce que je fais pour toutes mes apps, je les link de suite à des outils BI grâce aux WS. En l'occurrence nous utilisons Zoho Analytics, mais Power BI est très bien aussi.
Dans votre apps vous êtes capables sur un clic bouton un lien URL vers l'apps BI ou le tableau de bord. De plus ces apps BI sont très user friendly et eu cher. |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
138 messages
Popularité : +7 (7 votes) |
|
Posté le 13 octobre 2020 - 12:09 |
Bonjour, ayant été confronté à cette même problématique
la solution que nous adoptons pour afficher plusieurs milliers de lignes dans une table est la suivante
- remplir la table par programmation surtout pas de Databinding
- lancer une procédure stockée sur le serveur qui fait le travail et renvoie un buffer compressé (Allège le trafique réseau énormément)
- à la réception du buffer désérialiser le résultat sur une structure de données qui est mappée sur les colonnes de la table
- parcourir la structure et remplir la table par programmation
ci-après un exemple d'implémentation
remplir_patients(Table,cad)
Sablier(Vrai)
tablePatient est une structure
AdreesePar est une chaîne
Adresse est une chaîne
AgePatient est une chaîne
allergieConnue est une chaîne
FIN
table_serv est un tableau de 0 tablePatient
buffer est un Buffer
nbelems est un numérique
_max est entier = 0
k est un numérique
buffer = HExecuteProcedure(maconnec,"Proc_remplir_Patients",nbelems,cad)
Décompresse(buffer)
Désérialise(table_serv,buffer,psdBinaire)
TableSupprimeTout(Table)
i est un numérique
j est un numérique = TableauInfo(table_serv,tiNombreTotal)
FOR i = 1 TO j
TableAjoute(Table)
Table.AdreesePar[i] = table_serv[i]:AdreesePar
Table.adresse[i] = table_serv[i]:Adresse
Table.AgePatient[i] = table_serv[i]:AgePatient
Table.allergieConnue[i] = table_serv[i]:al
FIN
Sablier(False)
procedure stokée
Procedure Proc_remplir_Patients(nbelems,cad)
QUAND EXCEPTIONEXCEPTION DANS
tablePatient est une structure
AdreesePar est une chaîne
Adresse est une chaîne
AgePatient est une chaîne
allergieConnue est une chaîne
FIN
table est un tableau de 0 tablePatient
buffer est un Buffer
cle est chaîne
SI cad <> "" ALORS
cle = HFiltre(BDPatient,cad)
SINON
cle = "IDBDPatient"
HDésactiveFiltre(BDPatient)
FIN
st un numérique = 1
HLitPremier(BDPatient,cle)
TANTQUE PAS HEnDehors(BDPatient)
TableauAjoute(table)
table[i]:AdreesePar = BDPatient.adresséPar
table[i]:Adresse = BDPatient.adresse
table[i]:allergieConnue = BDPatient.allergieConnue
HLitSuivant(BDPatient,cle)
i++
FIN
nbelems = TableauInfo(table,tiNombreTotal)
Sérialise(table,buffer,psdBinaire)
HDésactiveFiltre(BDPatient)
Compresse(buffer,compresseLZW)
RENVOYER buffer
FAIRE
Trace(ExceptionInfo())
POUR i = 1 À ExceptionInfo(errNombreSousErreur)
Trace("Sous-erreur "+i+" : "+ExceptionInfo(errMessage, i))
FIN
FIN |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 14 octobre 2020 - 11:04 |
Salut @Amine, ton idée est bonne pour la surcharge réseau mais n'est pas plus rapide que le reste non ?
Je viens d'effectuer un test est cela me donne le temps de réponse suivant : Le traitement de 91732 éléments (côté serveur) a duré 0min 30sec 169ms
Après je n'est pas effectué le test sur le serveur a proprement parlé, peut etre que cela sera plus tolérable.
Dans ton bout de code, la chose qui prend du temps est la Sérialisation du tableau. |
| |
| |
| | | |
|
| | |
| |
Posté le 14 octobre 2020 - 11:26 |
Bonjour,
Demande à PC SOFT leur secret, puisque lors des TDF ils nous montrent l'affichage instantané de plusieurs milliards de lignes dans une table !
bon courage |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
138 messages
Popularité : +7 (7 votes) |
|
Posté le 14 octobre 2020 - 13:40 |
Effectivement la sérialisation peut prendre un certain vue la quantité de données à traiter, selon les performances du serveur le temps imparti sera plus ou moins long.
Ce qui est intéressent dans cette méthode c est que le goulot d'étranglement se situe au niveau du serveur, et toutes latence liée au réseau et aux allées et retours entre serveur et poste client sont minimisés au maximum.
L'avantage aussi c'est que les temps de réponses sont quasiment les même avec des connexions par internet ou LAN
toute l'optimisation est à gérer niveau serveur dans les procédures stockées qui doivent être optimales, vous pouvez remplacer les hlit... par des requêtes stockées ca peut améliorer les performances , ou minimiser le nombre de colonnes de la table (la structure à sérialisée ) |
| |
| |
| | | |
|
| | |
| |
Posté le 14 octobre 2020 - 15:28 |
Amine a écrit :
TableauAjoute(table)
table[i]:AdreesePar = BDPatient.adresséPar
table[i]:Adresse = BDPatient.adresse
table[i]:allergieConnue = BDPatient.allergieConnue
J'utilisais beaucoup cette écriture mais j'ai arrêté car elle est lente.
En effet, avec ce code ci-dessus, pour remplir les 3 colonnes d'une ligne de la table, il y a 4 instructions.
Il est plus rapide d'en utiliser une seule avec le code ci-dessous (les retours à la ligne et les commentaires servent à une meilleur lisibilité). Bien entendu, la maintenance est un tout petit plus compliqué si on ajoute une colonne au milieu de la table car il faut modifier cette instruction au bon endroit.
i = TableauAjouteLigne(table, BDPatient.adresséPar ,
BDPatient.adresse ,
BDPatient.allergieConnue )
Pour une vitesse améliorer, il ne faut pas oublier l'instruction
Table..AffichageActif=Faux
Avant la boucle de remplissage
et cette instruction à la fin du remplissage
Table..AffichageActif=Vrai |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
190 messages
Popularité : +21 (23 votes) |
|
Posté le 14 octobre 2020 - 15:54 |
Bonjour
je suis assez surpris des diverses méthodes employées.
nos tables sont basées souvent sur un tableau de structure
1 - On réalise une requête via une source de données.
2 - On utilise l'instruction FichierVersTableau(source, tableau)
3- tableaffiche
et un hannuleDeclaration de la source de données
Ca reste raisonnable comme délai sur plusieurs milliers de ligne
L'avantage est que chaque colonne est triable/filtrable rapidement. |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
119 messages
Popularité : +1 (1 vote) |
|
Posté le 16 octobre 2020 - 20:18 |
Bonsoir
J'ai aussi des problèmes de lenteur avec une table de 8500 lignes
Table fichier sur requete chargée en mémoire
J'utilise la fonction table..occurence pour afficher le nombre de lignes et je me suis rendu compte que cette fonction prenait plusieurs secondes (jusqu'à 20 s)
Avez-vous aussi remarqué cette lenteur sur la fonction ..occurence ?
bon week-end à tous |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
1 144 messages
Popularité : +50 (142 votes) |
|
Posté le 17 octobre 2020 - 12:40 |
La rapidité ne dépend pas seulement du réseau ou de la quantité de données pas aussi du serveur.
Pour traiter un grand nombre de données, on ne peut pas (à mon avis) se contenter des serveurs de bases que propose les hébergeurs.
Quelqu'un a-t-il fait le test avec un serveur de 8 processeurs (et pas 8 coeurs) et 128go de RAM (ou quelque chose s'en approchant ) ?
Car dans la démo de PC SOFT sur leur TD Tech c'est un serveur de ce type qu'ils utilisent.
J'ai les mêmes lenteurs que tout le monde avec un serveur dédiés chez Strato (1 proc 8 coeurs et 8Go de RAM).
--
Thierry TILLIER
Développeur Windev-Webdev
Formation Windev : https://coursdinfo.teachable.com/
Formation bureautique : https://coursdinfo.net |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
283 messages
Popularité : +80 (92 votes) |
|
Posté le 17 octobre 2020 - 13:41 |
Désolé Thierry mais on ne donne pas de solution tirée sur "son avis"
--
Les innocents sont toujours accusés à tord. |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
1 144 messages
Popularité : +50 (142 votes) |
|
Posté le 17 octobre 2020 - 15:57 |
1865555 Merci pour cette remarque constructive... on peut toujours remplacé "avis" par expérience, mais j'ai bien compris que vous avez une dent contre moi... à l'avenir abstenez-vous de me répondre et dites quelque chose d'utile à tout le monde.
--
Thierry TILLIER
Développeur Windev-Webdev
Formation Windev : https://coursdinfo.teachable.com/
Formation bureautique : https://coursdinfo.net |
| |
| |
| | | |
|
| | |
| |
Posté le 18 octobre 2020 - 14:31 |
Bonjour,
Une réflexion:
Selon le cas, est ce utile de "stocker" 85 000 enregistrements dans une table alors que visuellement elle ne peux qu'en afficher à l'utilisateur qu'une vingtaine, de plus, scroller 85 000 lignes apparait inefficace juste pour y rechercher un élément.
Surtout qu'a un instant T, le besoin de données ne concerne surement que quelques enregistrements ?
Une idée:
Placer sur un plan caché de la fenêtre plusieurs tables mémoire afin d'y stocker qu'une partie sérialisée des données issues directement du fichier, ce chargement même s'il prend un peu de temps n'a alors lieu qu'une fois.
Par la suite, dans les requêtes de recherches ou de filtrage par programmation (FAA désactivés), commencent par interroger les tables cachées avant d'en transférer le résultat vers la table principale en affichage.
Alain |
| |
| |
| | | |
|
| | |
| |
Posté le 18 octobre 2020 - 18:06 |
Bonjour,
Je constate comme vous une lenteur systématique dans l'usage de
..Occurrence tout comme d'ailleurs dans HnbEnr directement sur un fichier.
Je ne comprends pas pourquoi c'est aussi lent pour savoir de combien
d'éléments se compose un fichier, une table, un tableau ou une autre
variable.
Même si pas directement lié au sujet, je suis preneur de solutions dans
ce cas précis 
Bon dev à tous
Le 16.10.2020 à 18:18, "José" a écrit :
Bonsoir
J'ai aussi des problèmes de lenteur avec une table de 8500 lignes Table
fichier sur requete chargée en mémoire
J'utilise la fonction table..occurence pour afficher le nombre de lignes
et je me suis rendu compte que cette fonction prenait plusieurs secondes
(jusqu'à 20 s)
Avez-vous aussi remarqué cette lenteur sur la fonction ..occurence ?
bon week-end à tous
--
Fabrice M.
------------------------------------- |
| |
| |
| | | |
|
| | |
| |
Posté le 19 octobre 2020 - 14:37 |
..occurrence sur une table attend que le chargement de la table soit
terminé pour retourner un valeur, selon le mode de remplissage de la
table ca peut dont etre lent
de mon expérience hnbenr sur un fichier est toujours quasi instantané,
en revanche sur une requete ca demande là aussi d'attendre la fin de
l'exécution de la requete
eric l.
Le 18/10/2020 à 16:06, Fabrice M. a écrit :
Bonjour, Je constate comme vous une lenteur systématique dans l'usage de ..Occurrence tout comme d'ailleurs dans HnbEnr directement sur un fichier. Je ne comprends pas pourquoi c'est aussi lent pour savoir de combien d'éléments se compose un fichier, une table, un tableau ou une autre variable. Même si pas directement lié au sujet, je suis preneur de solutions dans ce cas précis Bon dev à tous Le 16.10.2020 à 18:18, "José" a écrit : Bonsoir
J'ai aussi des problèmes de lenteur avec une table de 8500 lignes
Table fichier sur requete chargée en mémoire
J'utilise la fonction table..occurence pour afficher le nombre de
lignes et je me suis rendu compte que cette fonction prenait plusieurs
secondes (jusqu'à 20 s)
Avez-vous aussi remarqué cette lenteur sur la fonction ..occurence ?
bon week-end à tous
|
| |
| |
| | | |
|
| | |
| |
Posté le 19 octobre 2020 - 14:41 |
c'est une bonne remarque perso je n'ai que des serveurs virtualisés en
exploitation depuis un moment et j'avais effectivement oublié que ca
impacte forcément les perfs...
eric l.
> Le 17/10/2020 à 10:40, THIERRY TILLIER a écrit :
La rapidité ne dépend pas seulement du réseau ou de la quantité de données pas aussi du serveur. Pour traiter un grand nombre de données, on ne peut pas (à mon avis) se contenter des serveurs de bases que propose les hébergeurs. Quelqu'un a-t-il fait le test avec un serveur de 8 processeurs (et pas 8 coeurs) et 128go de RAM (ou quelque chose s'en approchant ) ? Car dans la démo de PC SOFT sur leur TD Tech c'est un serveur de ce type qu'ils utilisent. J'ai les mêmes lenteurs que tout le monde avec un serveur dédiés chez Strato (1 proc 8 coeurs et 8Go de RAM). -- Thierry TILLIER Développeur Windev-Webdev Formation Windev : https://coursdinfo.teachable.com/Formation bureautique : https://coursdinfo.net |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
227 messages
Popularité : +18 (20 votes) |
|
Posté le 19 octobre 2020 - 17:58 |
Bonjour à tous,
Comme tous le monde je partage mon expérience sur le temps d'affichage s'en erreur d'une requete SQL dans une table Windev.
Il y a trois points de lenteurs
1 - L’exécution de la requete SQL sur le serveur HFCSQL
2 - Le retour de la requete SQL sur le poste
3 - Le chargement de la table
Ce que j’applique
1 -
Si vous pouvez virer HFCSQL pour un SQL serveur ou même un mysql foncé car si HFCSQL était plus performant, le moteur aurait été racheté par (microsoft, ibm), je pense que HFCSQL est à des années lumières des Leader.
Si comme moi vous ne pouvez pas faire autrement toutes mes requetes SQL sont construite de cette façon.
SELECT ==> avec uniquement les colonnes que j'ai besoin jamais de *
FROM
1. avec uniquement des [LEFT/RIGHT/OUTER] JOIN abandonné le where
2. avec le maximum de condition même celle du where
3. Jamais au grand jamais de concaténation de clef dans une condition faîtes un and/out/in/between des différentes clefs dans le join
4. In c'est mieux que and si vous utiliser plusieurs conditions (Rappel vos paramètres {pParam} doivent être séparer par ; et pas ,)
WHERE =>j'en met le moins possible
ORDER (Plus rapide qu'un filtre dans l'application)
Dernière chose, votre requete doit toujours être déclaré dans le projet dans la section requete je sais pas ce qu'il font mais c'est toujours plus rapide que quand je fais une variable requete SQL ou un chaine qui contient ma requete SQL pour les anciènnes versions.
2 - Si vous avez bien fait votre requete ben vous ne pourrez pas vraiment gratter du temps par programmation, je pense pas que haché ou sérialiser donne une grosse différence je n'est jamais fais de test. je fais juste attention que le réseau du client soit nickel et a jour.
3 - Pour le chargement de la table sa sera :
Table..AffichageActif=Faux
Hconstruittablefichier pour faire correspondre ma table au format renvoyé (pas forcément utile si les colonnes sont fixes)
FichierVersTableMémoire(TABLE_Résultat,MaSDD)
Table..AffichageActif=VRAI
Mais car il y a toujours un mais si vous avez de la chance et vous en aurez ^^ FichierVersTableMémoire aura une tendance à pas mettre toutes les lignes... mais c'est le plus rapide.
Quand je traite des données critiques je fais comme @ Nicolas CAILLIEZ je passe par un tableau (et des threads pour pas bloqué l'utilisateur)
Bien sur ne pas oublier le hliberrerequete()
Vous trouvez cela pas assez rapide ?
On passe au niveau supérieur mieux que la procédure stocké de @Amine mieux que la vue pour répondre à @THIERRY TILLIER
je vous présente la vue matérialisée
Vous faite deux requêtes
La première qui fait la recherche sur toutes vos tables qui fait les calculs les filtres et vous créé une vue matérialisée que vous métrez à jour plus tard avec hrafraichievue
La lenteur vous l'aurez toujours mais vous l'aurez que sur le serveur et pas au moment ou le client demande l'information
Vous faites une deuxième requete qui pointe uniquement sur la vue matérialiser qui apparait comme un fichier de votre annalyse si vous l'avez déclaré dans l’analyse
voir vous pouvez binder directe votre table qui s’occupera de charger/décharger la table au fur et a mesure du scroll.
La vous allez voir des temps d'affichage digne d'une présentation PC soft sans avoir besoin d'un serveur de tueur et bonne nouvelle tous les colonnes de la vues matérialisé sont indexés si je me trompe pas.
Vous pouvez donc ajouter des filtres dans la deuxième requete qui restera rapide car vous n'avez qu'une table
Pour répondre à ceux qui se plaignent de la lenteur de hnbenr c'est pas ça. hexecuterequete et hexecuterequetesql ne sont pas bloquant mais hnbenr() oui comme hlitpremier donc cela vous donne le temps de votre requete (aller - exécution - retour)
Note je préfère faire un pour tout MARequete au lieu d'un Hlitpremier/hlitsuivant(MARequete) 2 lignes vs 4 pour le même résultat
Le seul bémol de la vue matérialisée c'est que les données ne sont pas à jour il faut déterminé votre tolérance mais bonne nouvelle je crois que hrafraichievue restera plus rapide car le serveur HFCSQL gére tous seul en local.
voilà pour mon petit retour d'expérience sur le chargement des tables |
| |
| |
| | | |
|
| | |
| |
Posté le 19 octobre 2020 - 18:16 |
Oui, très juste, sur les fichiers la vitesse de HnbEnr est bonne et pas
sur les requêtes.
Merci d'avoir précisé mon propos même si tout cela est dommage vu que je
ne vois pas d'alternative
Le 19.10.2020 à 12:37, eric l. a écrit :
.occurrence sur une table attend que le chargement de la table soit terminé pour retourner un valeur, selon le mode de remplissage de la table ca peut dont etre lent de mon expérience hnbenr sur un fichier est toujours quasi instantané, en revanche sur une requete ca demande là aussi d'attendre la fin de l'exécution de la requete eric l. Le 18/10/2020 à 16:06, Fabrice M. a écrit : Bonjour, Je constate comme vous une lenteur systématique dans l'usage de ..Occurrence tout comme d'ailleurs dans HnbEnr directement sur un fichier. Je ne comprends pas pourquoi c'est aussi lent pour savoir de combien d'éléments se compose un fichier, une table, un tableau ou une autre variable. Même si pas directement lié au sujet, je suis preneur de solutions dans ce cas précis Bon dev à tous Le 16.10.2020 à 18:18, "José" a écrit : Bonsoir
J'ai aussi des problèmes de lenteur avec une table de 8500 lignes
Table fichier sur requete chargée en mémoire
J'utilise la fonction table..occurence pour afficher le nombre de
lignes et je me suis rendu compte que cette fonction prenait
plusieurs secondes (jusqu'à 20 s)
Avez-vous aussi remarqué cette lenteur sur la fonction ..occurence ?
bon week-end à tous
--
Fabrice M.
------------------------------------- |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 574 messages
Popularité : +222 (260 votes) |
|
Posté le 20 octobre 2020 - 09:57 |
Merci d'avoir précisé mon propos même si tout cela est dommage vu que je ne vois pas d'alternative
L'alternative est de faire une requête count(*) qui renverra le nombre d'enregistrement et donc plus besoin HNbEnr()
--
Cordialement,
Philippe SAINT-BERTIN |
| |
| |
| | | |
|
| | |
| |
Posté le 20 octobre 2020 - 11:57 |
Je n'y avais pas pensé et je vais essayer dans le cas du HnbEnr sur un
fichier. Merci pour l'idée.
Le 20.10.2020 à 07:57, Philippe SB a écrit :
Merci d'avoir précisé mon propos même si tout cela est dommage vu que je ne vois pas d'alternative L'alternative est de faire une requête count(*) qui renverra le nombre d'enregistrement et donc plus besoin HNbEnr() -- Cordialement, Philippe SAINT-BERTIN
--
Fabrice M.
------------------------------------- |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
31 messages |
|
Posté le 27 octobre 2020 - 10:27 |
Bonjour à tous, encore merci de l'intérêt que vous porter a ce poste, quelqu'un a pu tester les quelques idées cité si dessus et voir une différence notable ?
Bien à vous, Benjamin |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
190 messages
Popularité : +12 (12 votes) |
|
Posté le 27 octobre 2020 - 12:15 |
Bonjour
Ma proposition de n'utiliser que des tables mémoires non reliées a justement fait l'objet d'un test dans ce post...
a) 4.4s pour charger 200 000 lignes depuis une requête (hors temps de la requête mais qui est souvent négligeable avec un bon moteur SQL)
b) tris instantanés sans relance de requête ni affolement de l'écran
c) comptage des lignes instantané (une fois les lignes chargées)
Bref je ne changerai pas de méthode. Il faut aussi comprendre que les tables fichiers ne sont pas non plus adaptées à la mobilité (réseau en WIFI, appel de WS, perte de connexion etc...) C'est l'ancien monde connecté et je sais très bien de quoi il retourne en tant qu'ancien développeur paradox.
Oui cela parait très rapide en affichage et parcours mais les données ne sont pas en fait réellement disponibles d'où les soucis mentionnée lors des tris, du comptage etc... On ne peut pas tout avoir et personnellement mon choix est fait.
--
Côme, Clairinfo |
| |
| |
| | | |
|
| | |
| |
Posté le 07 septembre 2021 - 13:59 |
Bonjour,
@Côme : votre approche m'intéresse car j'utilise moi aussi SQLExec (et non HExecuteRequeteSQL) et ne puis donc pas utiliser FichierVersTableMémoire (<= qui me semble être la solution la plus performante de toute pour afficher les données dans une table). Du coup, je me contente d'un SQLTable() mais qui est systématiquement moins performante que FichierVersTableMémoire.
Et mes temps de réponse sont nettement moins rapides que ceux que vous mentionnez.
Pour 32.000 lignes ca prend 8s... Note importante: j'ai presque 60colonnes. |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
2 574 messages
Popularité : +222 (260 votes) |
|
Posté le 07 septembre 2021 - 17:58 |
Plus il y a de colonnes et plus c'est long. On peut jouer sur la propriété ..AffichageActif éventuellement.
--
Cordialement,
Philippe SAINT-BERTIN |
| |
| |
| | | |
|
| | |
| |
Membre enregistré
190 messages
Popularité : +12 (12 votes) |
|
Posté le 07 septembre 2021 - 18:30 |
Bonjour Greg
Les 60 colonnes changent un peu la donne c'est sûr. Vous avez vraiment besoin de toutes les afficher ?
Dans la logique client serveur on a souvent une vue table simplifiée qui affiche les colonnes les plus utiles puis à la demande on a une vue détaillée sur un enregistrement qui elle affiche toutes les infos. Ou alors vous êtes dans une logique requêteur SQL pour pouvoir peut-être exporter ? Mais dans ce cas le temps est moins important me semble-t-il car ce ne sont pas des manipulations usuelles.
Je pense que le temps se répartit entre le temps d'exécution de la requête et le chargement de la table mémoire.
Le chiffre que j'ai indiqué de 4.4 secondes ne concernait que le chargement des 200 000 records dans la table mémoire.
Dans mon cas le temps de la requête était peu important (Serveur MySql local sur mon poste, point important ici, et Table INNODB)
De mémoire j'avais simplement exécuté la requête par un SQLExec puis effectué un SQLTable, comme vous.
Mon PC n'est pas un monstre loin de là Acer Predator Intel i7 avec 8Go de RAM. Il n'y avait aucun code dans la table mémoire susceptible de ralentir le chargement. La table mémoire était en outre non reliée à un fichier.
Par ailleurs je ne pense pas qu'avec les ordres H on puisse avoir de meilleures performances, j'ai commencé à les utiliser sur un nouveau projet MySql car effectivement c'est pratique mais je n'obtiens pas exactement les mêmes performances ce qui me semble logique les ordres H et l'analyse rajoutant toute une gestion de meta données (structure des tables etc) que l'on a pas en SQLExec. L'instruction ConstruitTableFichier par exemple est pratique dans le cadre d'un requêteur SQL car elle détermine seule le type de toutes les colonnes et les ajuste mais... disons qu'elle prend son temps, mon code en SQLExec avec retraitement du type de colonne est nettement plus performant.
Hth
--
Côme, Clairinfo |
| |
| |
| | | |
|
| | |